This is a guest post by Graeme Blair, Jasper Cooper, Alex Coppock, and Macartan Humphreys
Empirical social scientists spend a lot of time trying to develop really good research designs and then trying to convince readers and reviewers that their designs really are good. We think the challenges of generating and communicating designs are made harder than they need to be because (a) there is not a common understanding of what constitutes a design and (b) there is a dearth of tools for analyzing the properties of a design.
We have been working to address these challenges over the last few years by developing a set of tools that helps researchers “declare” and “diagnose” designs before they implement them and lets readers review and interrogate designs easily.[i]
What do we mean by declaring and diagnosing designs? To make things a little more concrete, here is a simple example of a design declared and diagnosed, using our R packages (DeclareDesign and DesignLibrary):
my_design block_cluster_two_arm_designer(N = 500, N_blocks = 50, N_clusters_in_block = 2, ate = .2)
Here, in a single line of code, you create an object—my_design—that contains a complete description of a particular design. In this case, we declared a two-arm trial that uses blocked and clustered random assignment. Some features of this design are modified explicitly here, such as the basic data structure and the assumed average treatment effect. Other elements, such as the assumed distribution of errors across blocks and clusters, the assignment strategy (matched cluster pairs), and the analysis strategy (regression accounting for blocks and clusters) take on default values, but are nevertheless fully stipulated, accessible, and modifiable.
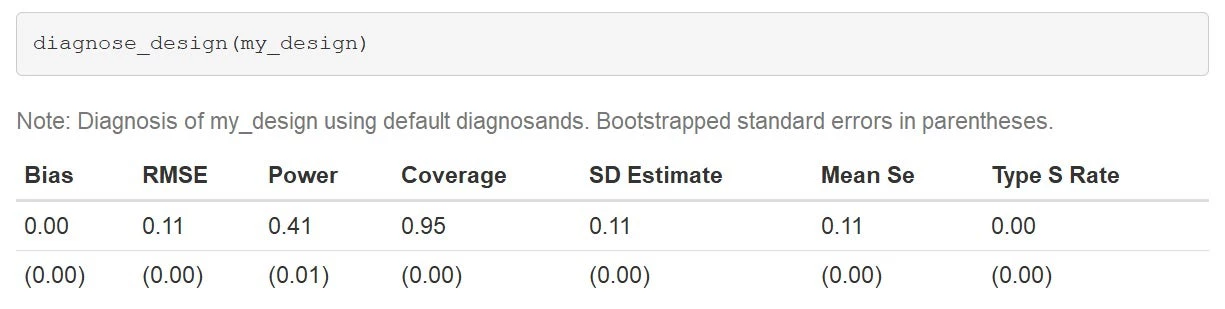
The diagnosis is done like this:
This diagnosis is done using a Monte Carlo approach in which the design is “run” many times, with different data draws, assignments, and so on. Looking at the distribution of what you find across runs lets you figure out the properties of a design. In this case the design we have declared is pretty poorly “powered” (most of the time the results from running the design are not statistically significant) but the estimator is unbiased (although the answer may not be right in any particular run of the design, it is right on average) and the standard errors perform reliably (“coverage” is close to 95%—that is, about 95% of the time the right answer lies within the confidence intervals produced by different runs of the design).
The idea of the DeclareDesign suite of software packages is to make this kind of exercise possible for a great range of canonical designs as well as arbitrary user-defined designs.
The bigger idea is that the tools encourage a shift towards thinking about designs as portable, self-contained objects that can be easily assessed for completeness and that can be shared, modified, and interrogated in a simple way. Ultimately, we hope, scholars will have access to a large library of declared designs, both canonical designs and actual designs used in prominent research.
What is design declaration and diagnosis?
Right now, there is not much agreement over what a research design
is. What information do you have to give readers for them to have an adequate understanding of your design?
Our answer is that a design is adequately declared when key properties of a design, such as power, bias, or expected error are calculable from the design. So, assessing design’s completeness depends on the questions you want to be able to ask of a design.
Generating a complete design likely requires that a researcher gives information about four things: their background model (a speculation about how the world works), their inquiry (a description of what they want to learn about the world, given their model), their data strategy (a description of how they will intervene in the world to gather data), and their answer strategy (a description of the analysis procedure they will apply to the data in order to draw inferences about their inquiry). Collectively in this paper we refer to these components as MIDA: Model- Inquiry- Data strategy- Answer strategy.
The one-line declaration of the block-cluster design above implicitly provided information about all four of these components. You can see the explicit declaration of each of these components for a design of this kind here.
If all four of these components are stated formally then it becomes possible to assess whether the data strategy and answer strategy in combination are capable of giving good answers to the inquiry, given the model. In other words, you can then diagnose the design to see if it works, and if not, what problems it has. The actual properties of a design that you care about (what we call the “diagnosands”) likely depend upon the study. In many cases, the questions might be about bias or power, but they could also be about quantities such as the probability that you update in the right direction or the probability that the right policy decision will be made. [ii]
Designs as portable, self-contained objects
A nice feature of formal design declaration is that designs can be thought of objects that can be shared and used. If you send me your declared design then I can open it up and inspect it, see what design choices you have made, and what assumptions you are making to justify your design choices. I can then look to see how your design performs under the conditions you assume, but I can also see how it would perform under alternative conditions I might be interested in. For instance, if you sent me the my_design object declared above then I could quickly do the same diagnosis. But I could also alter features of the design, such as the number of units, or assumptions about error structures, or assumptions about the underlying data generating process, and diagnose the modified design to see if I get the same rosy results.
A second nice feature is that once you have declared a design you can use the design not just for assessing design properties, but also for implementation. If a design contains your sampling strategy, your assignment strategy, your analysis strategy, and so on, then you can actually use the design object to do all these things. For instance, the R command fake_data
Why do it? We’re encouraging people to try declaring and diagnosing research designs before implementing them. This can be done relatively quickly if you work from designs in the design library. But if you are going from scratch, doing a good job declaring a design can take time. So, it’s critical that the exercise be worth it.
No surprise, we think it is worth it. We imagine a range of benefits from design declaration. Chief among these:
- Improving designs. If researchers declare designs ex ante they can adjust properties of designs to improve them. An obvious benefit is to be able to calculate the power, or other properties, of arbitrary designs. By the same token, researchers can quickly assess the performance of different types of estimators for different types of data structure, or the gains and risks associated with different types of sampling or assignment strategies. Perhaps the greatest design gains from declaration come from getting answers to questions that you would otherwise not have asked.
- Communicating designs. Being able to send someone a fully declared design removes all ambiguity from key features of a design such as sampling procedures or analysis procedures. Posting a design declaration ex ante thus supports advanced forms of pre-registration.
- Sharing designs. Design development is a public good. A good design can be modified and used by others. Sharing a fully formalized design gives others a leg up in declaring designs appropriate to their problem.
- Facilitating critique. When you share a design, you make it easy for others to check its properties, but you also make it easy for others to assess how much the properties of your design depend on your assumptions about the world. A researcher might provide a diagnosis under one set of assumptions about the world. If they share their design object, a worried reviewer could modify it and see how things look under different assumptions about the world. Being able to do this could be useful for research funders also. In principle, for example, it can make it easy for a funder to assess what the gains would be from changing sample sizes or to specify their own desiderata as “diagnosands” for research designs that they want to support.
An Illustration: Difficult Design Choices for Factorial Experiments
Here is an example of how declaration and diagnosis help answer design questions for a fairly common design—including questions that you might not think of asking if you didn’t engage in design declaration in the first place.
Sometimes researchers have to choose between employing a two-by-two factorial design or a three-arm trial (where the “both” condition is excluded). Should I divide the group in three and give cash to some, business training to others, and maintain a third group as a control? Or should there be a group that gets both cash and training (factorial)? The choice raises questions of power: which design is more powerful?
The answer to that question depends acutely on the estimand: the exact causal question of interest. So let’s be clear about that. Say your primary interest is the effect of each treatment conditional on the other treatment being in the control condition.
Given this inquiry, the three-arm trial seems natural and allows the two comparisons easily. However, there is an interesting argument given in Fisher (1926) that suggests you might be better off going with the two-by-two factorial design. [iii] The reason is that in a three-arm trial you get to use two-thirds of your data for each comparison, whereas for a two-by-two trial you get to use 100% of your data for each comparison, since you get to observe the effect of each treatment conditional on both values of the other treatment.
So far so good. Say now that when you come to specifying a data generating model as part of the design that you realize that there may be interaction effects between the treatments. For example, the training affects the way the cash is used. This possibility gives rise to at least two questions:
First: Do interaction effects introduce a risk of biased estimates? If so, how great is the bias/efficiency tradeoff?
Second: Will I be able to measure interaction effects with any accuracy? What is my power for the “interaction term”?
Both of these questions are quite hard to answer with existing tools. Indeed, often neither is asked. But these questions get answered naturally as part of design declaration and diagnosis.
We illustrate here, imagining a world in which each treatment on its own has an effect of 0.2 but combined there is an effect of 0.6 (this implies a positive interaction of 0.2 points). We declare a factorial design and a three-arm design, specifying the estimand of interest, and diagnose:
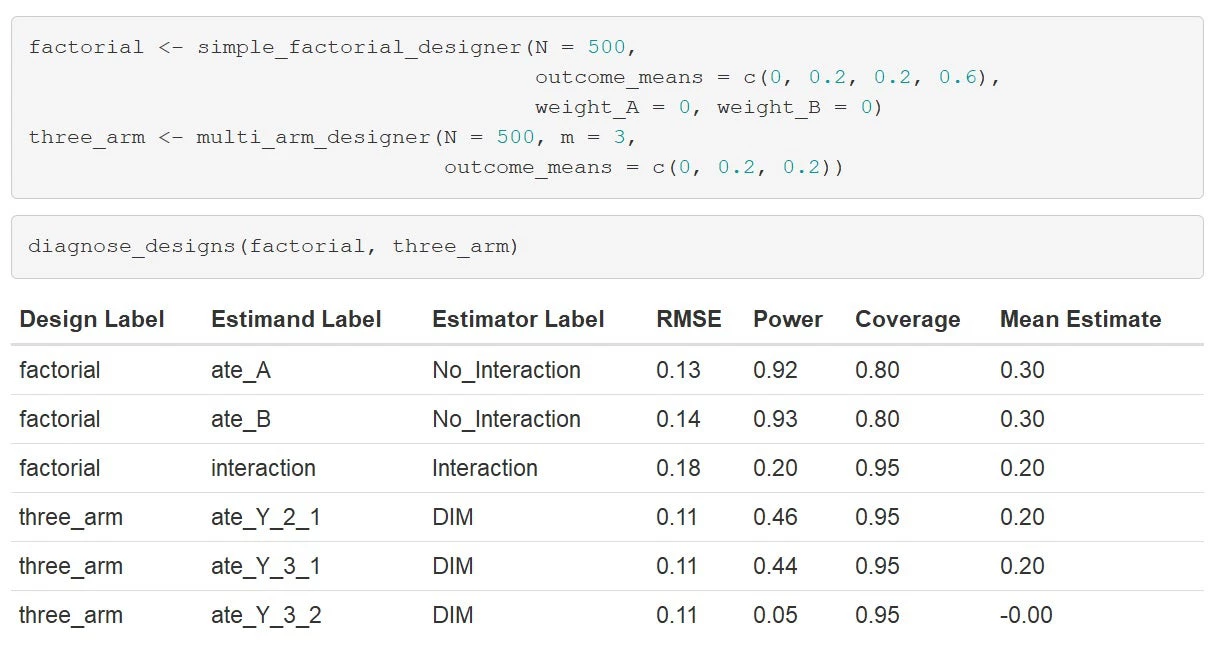
The figure below represents the results from doing the same exercise over a range of possible interaction effects. It clarifies that if there are weak interactions then you get efficiency gains from the factorial without introducing bias; if there are strong interactions then the bias may trump these gains. For this inquiry, the factorial seems to make most sense when you might least expect it: when there are no interactions. The diagnosis also clarifies how poor statistical power can be for assessing weak interaction effects. And if in doubt, it also points out that if the interaction improves your power it does so only for the biased estimate.
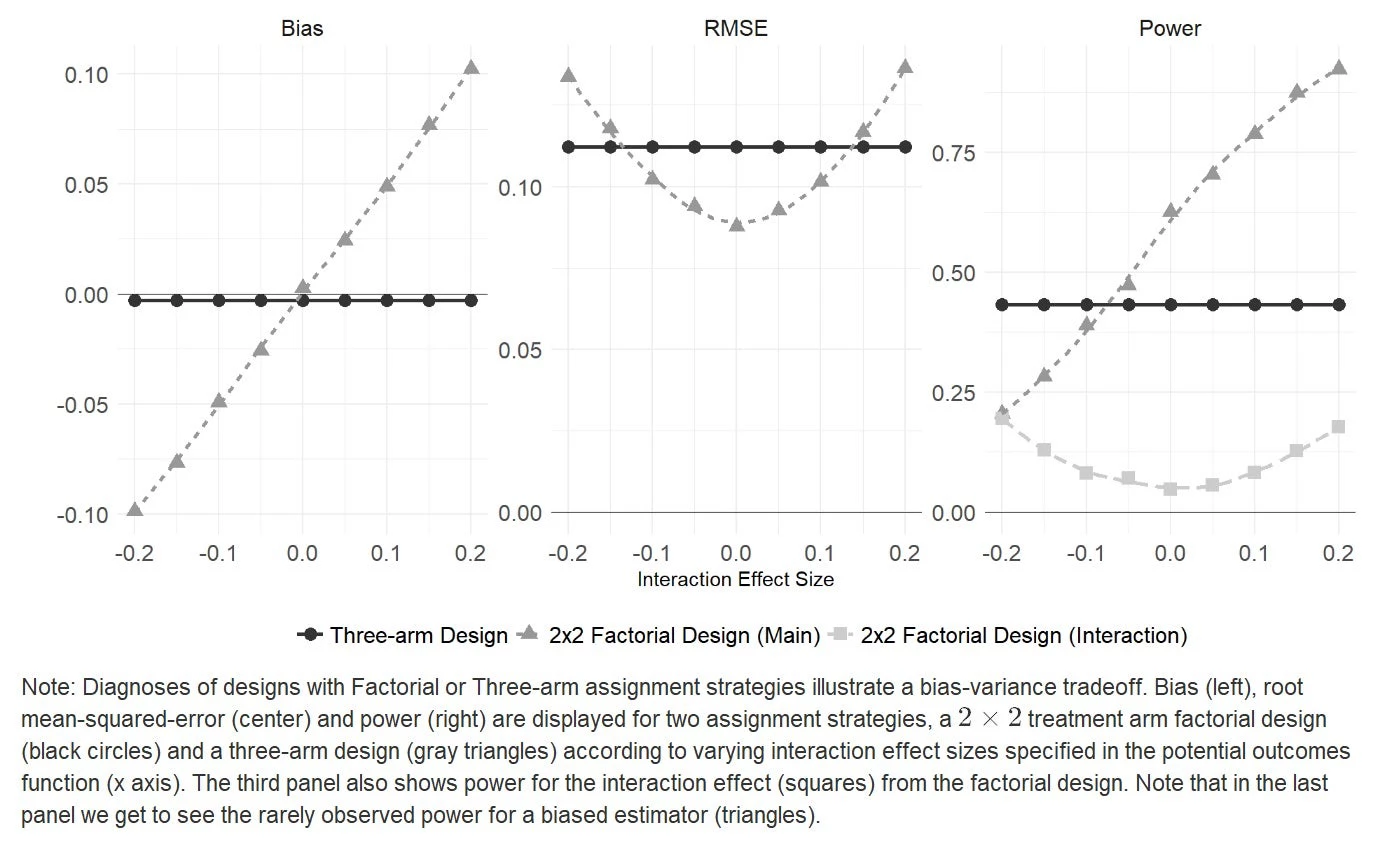
So, design declaration and diagnosis can make it possible to answer specific design questions as we’ve done above, conditional on conjectures about the world.
As we see it though, the biggest gains from design declaration and diagnosis are not in providing a tool to learn about general principles about research like these. The biggest gains are in forcing these questions on us as researchers during the normal course of planning research. The bias that can arise from factorial designs depends critically on how the estimand is defined and is only apparent when estimands are formally stated. Researchers often worry about the power of main effects but do not ask about the power for estimates of other estimands (or, for that matter, the power of biased estimators). Researchers may be able to answer these questions using first principles but if they are not in the habit of specifying estimands for each estimator the questions mightn’t get asked. If, however the estimands are declared and the properties of designs to assess them diagnosed as a matter of course, these answers are provided whether or not researchers ask the questions in the first place.
Scope
What sorts of designs are declaration good for? For some types of research that is by its nature open-ended, design declaration may not be possible. However, we think that the range of designs that can be declared in this way is very broad. We’ve been able to declare observational designs like two-way fixed effects models, IV designs, regression discontinuity designs, synthetic control, and matching; We’ve declared many experimental designs: blocked, clustered, adaptive, factorial, partial population; we’ve declared qualitative designs like QCA and process tracing. So far, the framework appears flexible enough to accommodate a large variety of research designs, but not so flexible that it’s meaningless.
Next steps
We are continuing to develop functionality for design declaration and are trying to do all this as a big open science project. If you like where this is going, there are lots of ways to take part.
- Most of the core packages have been written in R and are already available on CRAN, with more to come. R lovers you can contribute to these via pull requests on https://github.com/DeclareDesign.
- We are now working on expanding the design library. Our hope is that the library will contain not just canonical designs but also declarations of actual designs used in prominent social science research. We welcome contributions to the design library. Short of that we welcome suggestions for common designs that should be in the library. You can post these on our wiki here.
- We will start posting occasional blog posts while we write the book. These posts will be aimed at using declaration and diagnosis to address thorny design questions researchers routinely face. Send us your favorite design puzzles and we will see if we can declare them.
- We know that many people love Stata. We are working now on developing a basic Stata version as proof of concept. Stata lovers, if you want to contribute to the development of Stata functionality, we’d welcome you warmly.

Join the Conversation