Last weekend, I attended a conference, titled “Innovations for Shared Prosperity” at Stanford University, jointly organized by, among others, the Golub Capital Social Impact Lab and Microsoft Research. It brought together venture capitalists, entrepreneurs, and researchers together, who are all interested in finding solutions to the problems of poor people, with a focus on the U.S. A very different setting than the typical economics conferences that I frequent, and a little intimidating, but I enjoyed it in the end and, more importantly, learned some things.
One of the sessions I really enjoyed was the health plenary, which featured two UC Berkeley researchers. Jonathan Kolstad gave a nice talk on the US health insurance markets - some of the reasons the Affordable Care Act ran into problems (states opting out did not help), along with interesting statistics contrasting the poor and the rich in the US with other developed nations (news flash: rich in the US do as well as anyone else in the World. The US lags other industrialized nations in health outcomes because of vast inequalities in health, which the speaker called a “uniquely American issue” among rich countries). Given the conference's focus, he also discussed the complicated roles of technology (such as AI-based decision support for people shopping for insurance in the exchanges) and behavioral economics in making markets and policies work better. You can find Dr. Kolstad’s papers here.
But the paper that is much more up my alley was presented by Ziad Obermeyer, a physician and a researcher who works at the intersection of machine learning and health at Berkeley Public Health. He talked about Osteoarthritis and how machine learning can help people suffering from it (economists not interested in health: don’t leave. There are lessons here for all of us). The study, “Diagnosing bias with machine learning,” is joint work with Emma Pierson, Jure Leskovec, David Cutler, and Sendhil Mullainathan [the manuscript is under review, so please excuse the slides that redacted the exact numbers from the study, as per copyright rules in biomedical and public health journals. I thank the authors for sharing the redacted slides with me for the blog post.].
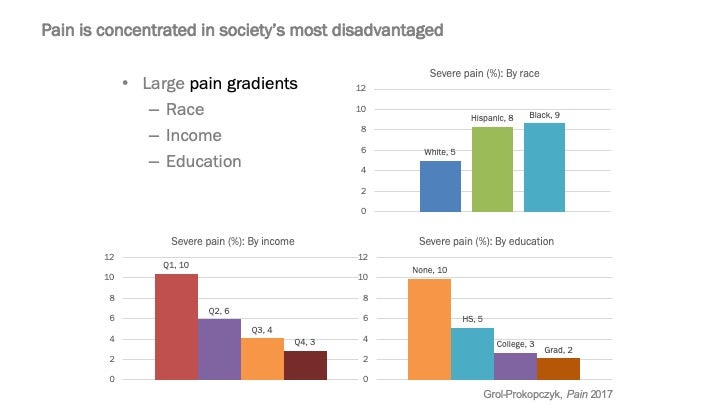
As you can see a significantly larger share of people of color or those with low income or education report being in severe pain in the U.S. A plausible explanation for this might be that such people are more likely to suffer from painful conditions: for example, individuals with a high school or less are 60% more likely to suffer from arthritis of the knee compared with people who have graduate degrees.
However, conditioning on such outcomes does not appreciably reduce the “race gap” in pain. For example, you can look at two people with very similar x-rays: the patterns in the above figure still hold at every level of disease severity discerned by medical professionals from the x-ray. There could be explanations for this, too: for example, stress can make an ailment more painful; there could be differences in access to/uptake of therapies to reduce pain, etc.
But, let’s take a step back for a second. What do we mean when we say that there is a persistent “race gap” in pain? Let’s zoom in on the osteoarthritis case:
- Someone complains of pain in their knee
- Doctor orders an x-ray and finds it to “look normal.”
- Doctor decides that pain must have another cause.
Dig in deeper: how does the doctor examine the x-ray and make a verdict?
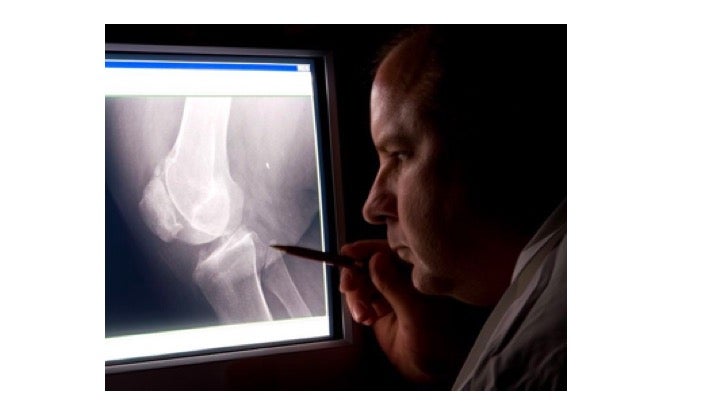
Maybe the doctor is wrong: where does the checklist by which he scores/grades the x-ray come from? In this case, from two researchers who studied coal miners in Lancashire, England in the 1950s. Those original papers that underlie the objective grading systems used to diagnose knee arthritis today did not mention the race of the subjects – perhaps because there was no heterogeneity along this dimension in the study population. Be that as it may, that’s what doctors use today: a grading scheme based on a 1950s, likely mostly white, English population. Could the doctors be under-diagnosing knee problems among minorities and disadvantaged segments of the population? Sure…
This is where a machine learning algorithm could help: machines have been getting consistently better in vision and speech recognition and they now beat humans in visual recognition. So, could they be trained to diagnose osteoarthritis?
Yes, but the problem is that we don’t know the gold standard: this is not like the case of the photo above, where we do know that it is a cat in the trough. All we have for knee arthritis are the x-rays and the grade assigned by the human radiologist. Obviously, since we suspect the latter to be biased, it is exactly not what you want to train the algorithm on…
This is where Dr. Obermeyer and co. had a good idea: train the algorithm on the level of pain reported by the patients instead. Well, but where do you get the data for that? The x-rays and radiologists’ interpretations of them are routinely available on hospital’s “picture archiving and communication” (PACS) systems. But, patient ratings of pain associated with that knee are much harder to come by. By some sheer luck, the authors were able to access data from a study that had all three data points. Once they did, training the algorithm was not hard: feed a bunch of x-rays and pain scores and eventually ask the algorithm to predict pain by just looking at the x-rays. Not only the algorithms can do this task well, but the authors also note that if the machine predicts significant pain from the x-ray, then the pain must be in the knee!
Well, with the algorithm trained on patient reports of pain to use x-rays to predict pain (and, by implication, severity of disease), what happens? First, that pesky dummy variable for race showing a large gap, which would not budge when adjusting for grades assigned by humans, declines by approximately half. What’s really interesting is that if you limit the x-rays to white knees only during training, the performance of the algorithm gets worse: so, a lot of the action is in the diversity/representativeness of the sample that the algorithm (or, even the human) is trained on. Furthermore, the algorithm seems to be finding real signals, not re-learning and re-adjusting what radiologists do.
And, this is all really very important here. Osteoarthritis can be very painful and debilitating and a knee replacement surgery can be life changing. But, for that surgery to be offered to you, you need to be diagnosed by a doctor as having severe arthritis of the knee. So, if you have severe pain, but a disbelieving radiologist, you are out of luck and that sounds absolutely terrible. The authors find that if we used their algorithm for diagnosis instead of a human, the share of black people in the US who receive knee replacement surgery would roughly double. That’s twice as many black people with a new life and a much lower number of people on oral pain medication, including opiates.
The bit about digging deep to find out where our baseline information comes from really did resonate with me. Generally, in my new projects, I love taking on the role of doing the literature review – I just enjoy jumping from paper to paper, going backwards in time, finding interesting work done decades ago. However, sometimes the information we rely on might have its limitations, leading us astray – as in the example of humans diagnosing knee arthritis. In a current project on counseling young women on modern contraceptives, we are relying on older studies on typical side effects of each method. But, what are the populations in those studies? Do I have reason to think that they extrapolate to my setting today? If not…
Actually, if not, we can do the same thing Dr. Obermeyer and co-authors have done in theirs: we do observe young women’s choices of contraceptive method, after which we will follow up with them regarding discontinuation and switching of these methods and the reasons why, including side effects. We can then retrain our counseling methods on these reports in a continuous feedback loop to improve on the original evidence that the counseling method currently relies on. I have discussed this with the authors and plan to follow up…
This is perhaps especially relevant in the authors’ effort to create an open data platform, bringing together health organizations and researchers around medical data linked to real outcomes (see the last slide in the PPT). We hope to contribute the data from our trial into the Nightingale project and, in turn, benefit from collaboration and machine learning to improve our intervention.

Join the Conversation