In a recent post, I described a randomized experiment in Jordan that I (along with Matt Groh, Nandini Krishnan and Tara Vishwanath) have been working on. The pilot program aimed to increase labor force participation and work experience of young women graduating from community colleges through two interventions: a wage subsidy program which gave the graduate a voucher she could take to a firm when looking for work, with the voucher paying the firm a subsidy equal to the minimum wage for hiring her for a period of up to six months and soft skills training, where the graduate was invited to a 45 hour training course covering key soft skills employers claim graduates are often lacking.
We then invited our readers to give their expectations of the likely impacts of such programs at the time of a midline survey (taken while the subsidy was still in effect, 8 months after graduation), and at endline (taken 4 months after the subsidy had ended, and 16 months after graduation). I also carried out this expectations elicitation exercise midway through seminars presenting the results at the University of Virginia, Paris School of Economics, the World Bank and IADB.
So first, what were the results of the pilot?
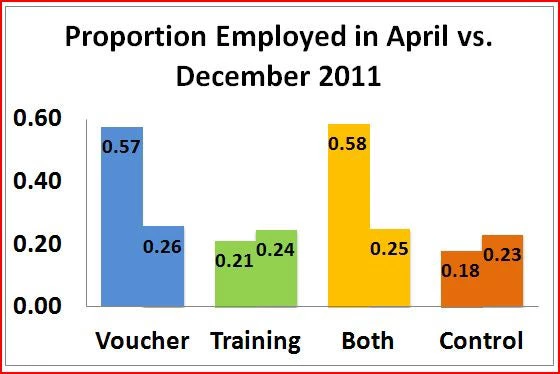
A draft of the paper is available here. Figure 1 below shows the proportion employed by treatment group at the midline (April 2011) and endline (December 2011). The headline result is that the job voucher led to a massive increase in employment while the subsidy was active, but that this impact mostly disappeared once the subsidy ended. This impact was similar whether students just got the subsidy, or got the subsidy combined with the soft skills training (the “both” group on the graph). Soft skills training by itself had no significant impact in either survey round. The job voucher did succeed in giving graduates more work experience, and resulted in higher labor force participation at the endline, but does not appear to have led to lasting employment effects over the time period measured.
The Results of the Expectations Elicitation Exercise
A common refrain following the presentation of experimental results or results from other rigorous impact evaluations is often that the findings “will surprise no one who had opened an economics textbook” (Scheiber, 2007). A novel feature of this study is to provide a way to quantify the extent to which the findings are novel or unexpected through elicitation of audience expectations. Figure 2 provides histograms of the resulting expectations, with the black vertical lines showing the 95 percent confidence interval for our treatment estimates:
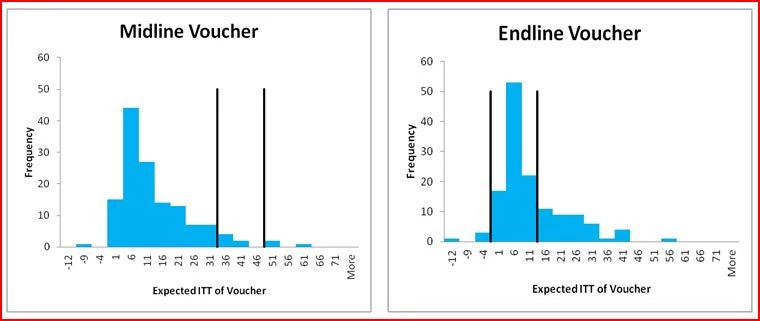
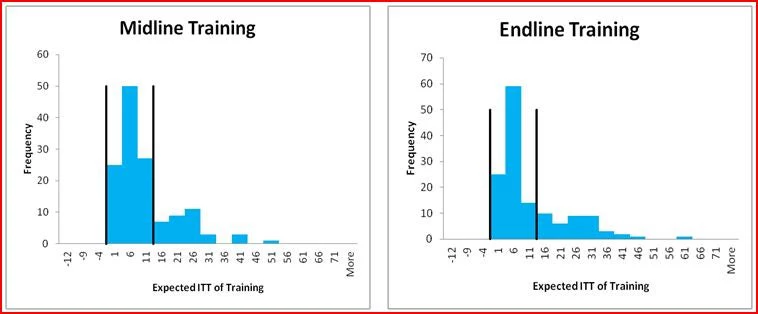
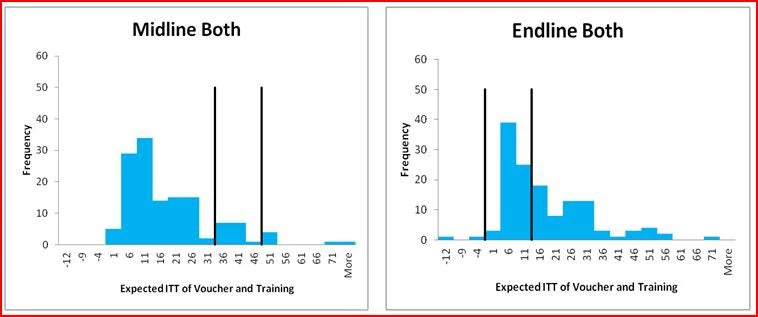
Several results are notable:
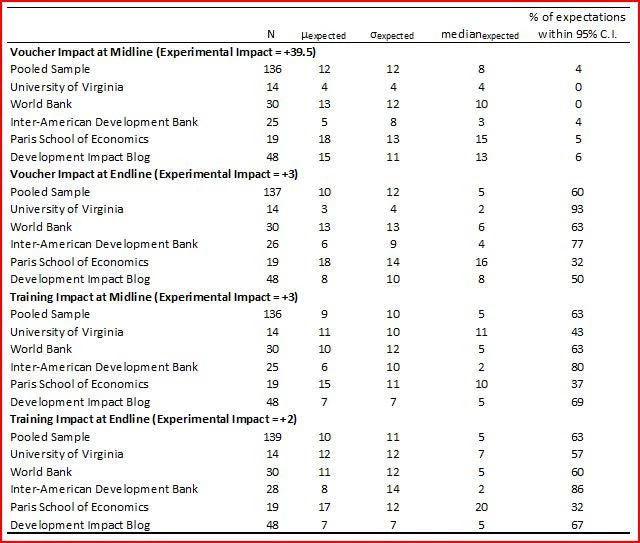
· The strong impact of the voucher in the short-run was a surprise to almost everyone: only 4 percent of the 136 respondents gave an expected value of the voucher impact at midline that lies within the 95 confidence interval of the treatment effect, with the median expected impact of 8 percentage points less than one-quarter of the actual impact of 39.5 percentage points.
· Modal expectations were relatively accurate for the longer-term impact of the voucher, and for the soft skills training, although mean expected endline impacts were 10 percentage points for both relative to actual effects of 2-3 percent, reflecting a long right tail of the distribution.
· There is substantial heterogeneity in beliefs about program effectiveness: the standard deviations of expected impacts range from 10 to 15 percentage points.
· Audiences believed the combination of the voucher and training was likely to have larger impact than either treatment alone
· None of the respondents had all six of their expectations lie within the 95 percent confidence intervals of the actual impacts.
· There was considerable heterogeneity among respondents in their relative rankings of the interventions: at midline (endline) 59 (47) percent thought the voucher would have a larger impact than the soft skills training, 11 (14) percent that the impact would be the same, and 30 (39) percent that the voucher would have less impact than the soft skills training.
So which group was most accurate? And is online elicitation very biased?
Dean Karlan and Annie Duflo have also recently been obtaining qualitative expectations about the impacts of a program through polls on the Stanford Social Innovation Review. See here for an example. The advantage of online elicitation is that it opens up the elicitation to a broad audience, but downsides compared to elicitation in a seminar setting are less time to explain carefully the details of the intervention, and selective response – we had 50 responses to our online poll which is perhaps 3-5% of those who may have read the blog post – consistent with click-through rates Berk and I have found for links to academic papers. The question is whether this leads to systematically different expectations from those in academic or policy audiences?
The following table shows the mean, standard deviation, median, and percentage of expectations that lie within the treatment effect confidence interval by subsample. We see that:
· Development Impact blog reader’s expectations are in fact very similar to those of the World Bank seminar audience (despite only 20% of the respondents to the blog poll being from the World Bank). So the self-selection into responding doesn’t seem to make too much difference in this case.
· If I define total error as the sum of the absolute difference between the experimental ITT and the expectation for each of the 6 estimates elicited, then blog readers win the prize for most accurate – although with an average total error of 82 percentage points, or 13.7 per outcome, this is still not that accurate. The Paris School of Economics audience has the highest average total error of 112 percentage points, or 18.7 per outcome. This comes largely because PSE audiences thought soft skills training would have larger long-term effects – perhaps reflecting European audiences being more likely to think active labor market policies will have lasting employment effects?
· In our international organization match-up, there was no significant difference in the average total errors of World Bank versus IADB audiences – this comes from the IADB audience basically thinking nothing will work, and so having high error on the short-term effect of the vouchers but getting the other outcomes approximately right, whereas the World Bank audience gets the midline voucher effect less wrong, but are more likely to overstate the training and longer-term voucher effects.
· The three most accurate individuals in terms of expectations were all blog readers- three students (two male, one female) located in the United States – congrats!

Join the Conversation