There is a proliferation of economics blogs, with increasing numbers of famous and not-so-famous economists devoting a significant amount of time to writing blog entries, and in some cases, attracting large numbers of readers. Yet little is known about the impact of this new medium. Together we are writing a paper to try and measure various impacts of economics blogs and thought we’d share the results over a few blog posts – and hopefully get useful comments to improve the paper at the same time.
Question 1: “Do blogs lead to increased dissemination of research papers?”
We examine this question by using abstract view and download statistics from Research Papers in Economics (RePEc), matched to the dates that blogs link to these papers. A few graphs dramatically illustrate the potential of blogs to draw attention to research papers.
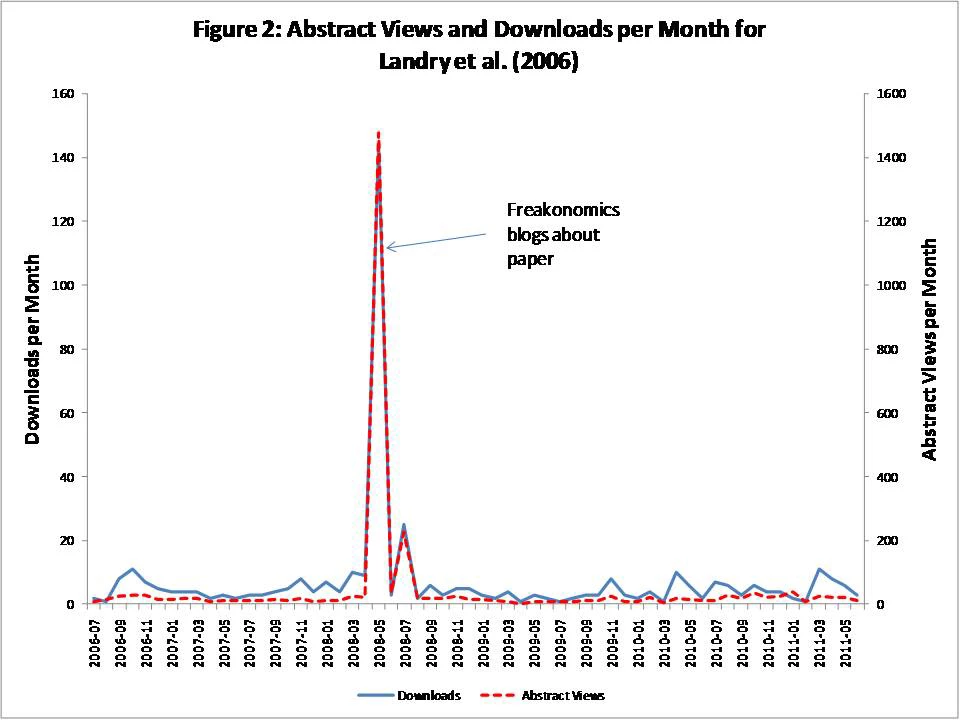
Example 1: Freakonomics blogs about a paper
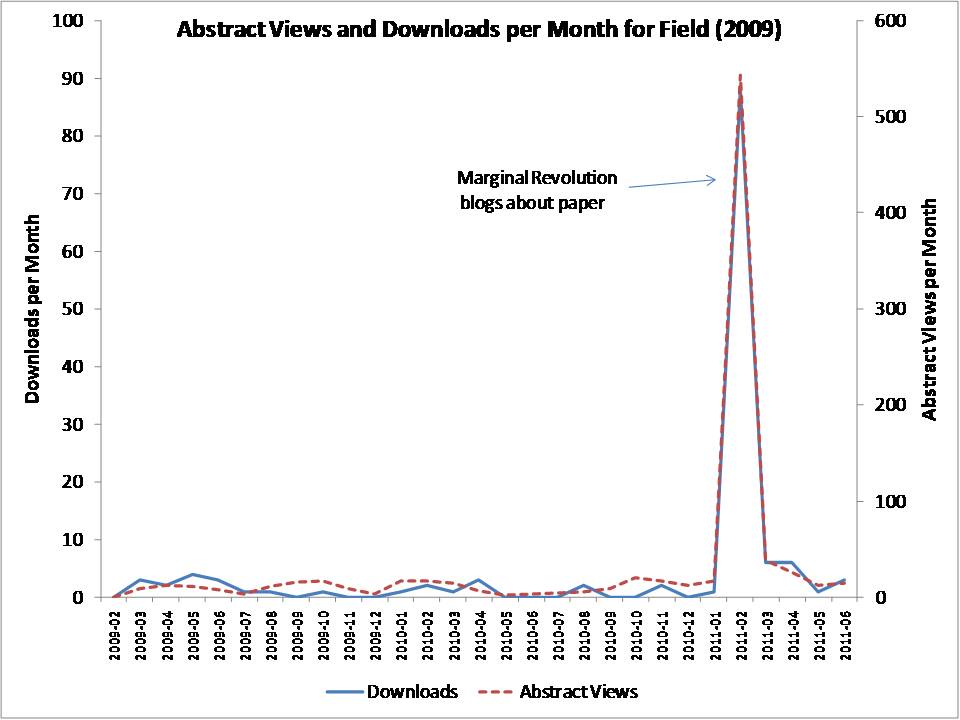
Example 2: Marginal Revolution blogs about a paper:
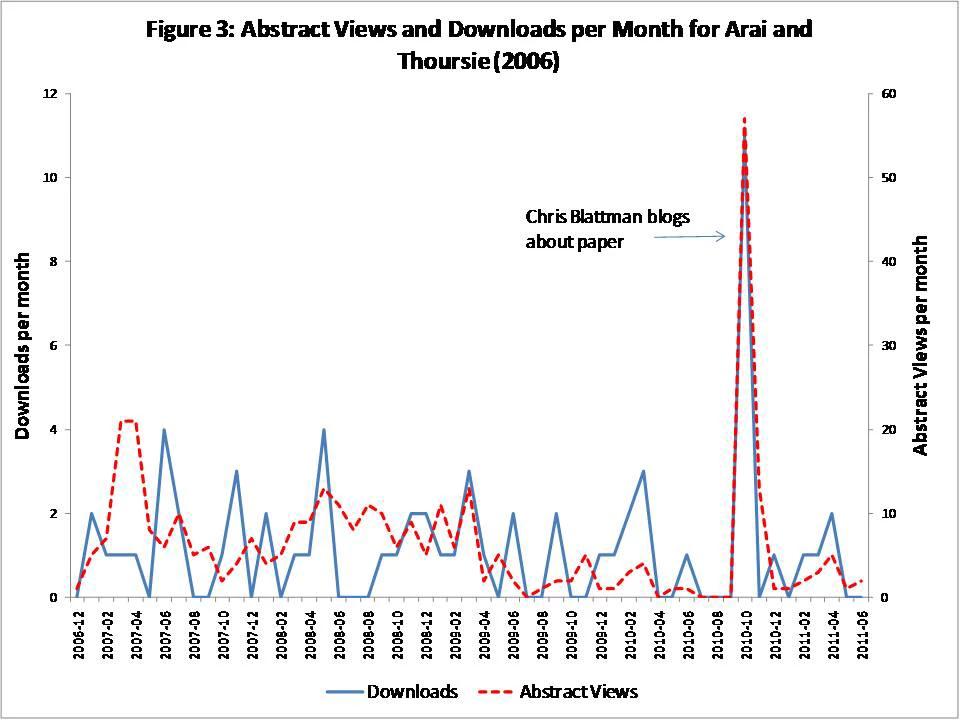
Example 3: Chris Blattman blogs about a paper:
Ok, so there seems to be something there. To formally test for the impact of different blogs on abstract views and downloads we put together a database of 94 papers linked to on 6 blogs: Aid Watch (before it ended), Chris Blattman, Economix (New York Times), Marginal Revolution, Freakonomics, and Paul Krugman. We define t=0 in the month in which the blog entry occurred, t=-1 in the month before, t=+1 in the month after, etc. Then we estimate the impact of blog s linking to a paper i via the following regression:
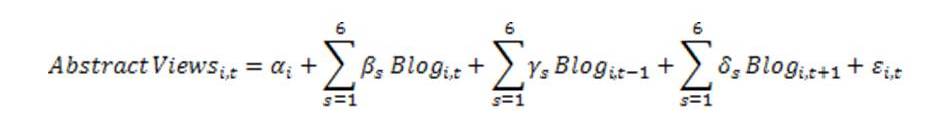
This controls for paper-specific fixed effects, and looks for a spike in views in the month the paper is blogged about, tests whether this continues into the next month, and also includes a lead term to rule out reverse causation whereby a paper gets a lot of downloads for some other reason, leading people to blog about it. For robustness we also include paper-specific linear time trends.
Results can be summarized as follows:
· Blogging about a paper causes a large increase in the number of abstract views and downloads in the same month: an average impact of an extra 70-95 abstract views in the case of Aid Watch and Blattman, 135 for Economix, 300 for Marginal Revolution, and 450-470 for Freakonomics and Krugman. [see regression table here]
· These increases are massive compared to the typical abstract views and downloads these papers get- one blog post in Freakonomics is equivalent to 3 years of abstract views! However, only a minority of readers click through – we estimate 1-2% of readers of the more popular blogs click on the links to view the abstracts, and 4% on a blog like Chris Blattman that likely has a more specialized (research-focused) readership.
· There is some spillover of reads into the next month (not everyone reads a blog post the day it is produced), and no evidence that abstract views and downloads lead blog posts.
A more formal write-up of this section of the paper and the table of results can be found here. We’d love to hear any comments and will incorporate them as appropriate into the paper we’re writing.
If you want to play around with the data yourself and vet our analysis, here is the Stata data set and do file. Let us know if you think we should be trying other specifications or you can’t replicate our results, etc.
Look out for our next installment Thursday, when we ask if blogs increase influence.


Join the Conversation