Motivation
Real-time data quality checks have become a well-established best practice for surveys (see the Development Research in Practice Handbook and JPAL Resources). Running systematic, high-frequency checks has a clear positive impact on survey data quality. As development researchers have increasingly turned to non-survey data sources (Currie et al. 2020), a trend accelerated by COVID-19, it’s time to ask: can we translate the data quality gains from real-time survey checks to the big data context? In our experience, there are more commonalities across data sources than you might expect. Just as a shift to electronic survey software enabled the broad adoption of high-frequency checks, new cloud computing resources and data processing tools now enable real-time checks of big data.
While the companies collecting these data often do internal quality assessments, repurposing big data for economics research typically requires additional quality checks to account for the fact that the data were not purpose-built to answer the specific research questions in mind. Therefore, quality assurance done by data scientists (e.g., the data quality framework from Agile Lab) needs to be combined with specific checks to ensure big data sources result in high-quality research inputs. In this blog post, we propose four general principles for specific quality checks which can be applied to a diverse array of data sources. In the second half of the blog, we explain how to put these principles into practice with big data and provide specific examples.
General principles
All real-time data quality checks should adhere to the same four principles, regardless of data source:
- Completeness: verify that all the expected data points actually appear in the dataset. Check if there are duplicates and whether the data is complete across time, space, and units of observation. Where feasible, compare the data received against other sources of data about the relevant population (such as a sampling frame or census) to establish whether coverage is complete.
- Consistency: check that values align across variables in ways that are both internally consistent and consistent with expectations, given knowledge of the local context and other relevant data sources.
- Anomalous data points: check that all of the data points fall within an expected range and identify any unusual or implausible values.
- Real-time: these checks are applied as soon as the data is received, so data quality issues can be identified and resolved in an actionable timeframe.
Big data checks in practice
We have seen a large increase in the use of non-traditional sources of data at the Development Impact Evaluation group (DIME) in recent years, including real-time and big data sources (Figure 1). What do we mean when we talk about real-time data or big data? A few examples from our work at DIME include: data on traffic or speeds extracted in real-time from platforms like Waze, Google maps, or Twitter; cell phone data that is aggregated by providers; market data from online shopping platforms; real-time sensor data on driving behavior or pollution. In all of these cases, we can apply the general principles outlined above and conduct a few simple, but important checks.[1]
Figure 1 - Data sources used by DIME projects

Note: the year shown on the x-axis corresponds to the year the project started, even if the data was only acquired later. Percentages add up to more than 100 since projects may have multiple sources of data.
Completeness
How to: In a survey context, checking for completeness can be as simple as comparing the responses received to the sampling frame. In the big data context, checking for completeness is not as straightforward, but it is essential. Completeness can be affected by challenges like unresponsive servers, bugs in the data extraction code, cell phone tower outages, a sensor’s wifi malfunction, and others. Some of these issues may be resolved if identified quickly, and those which cannot should be described in the data documentation. To check big data for completeness, follow three steps: First, verify that there are no duplicate observations. Second, check whether the data is complete across time, space, and units of observation, as applicable to your data. Visualizations of the full dataset are a good way to quickly reveal gaps. Third, whenever possible, assess completeness compared to other data sources.
Example: Figure 1 illustrates two different completeness checks performed on real-time data. Panel (a) graphs the data received over time, while panel (b) graphs it over space. In both cases, it is immediately clear when data is missing. Combining the information from the two graphs facilitates the identification of possible causes for the missing data.
Figure 2 - Completeness checks
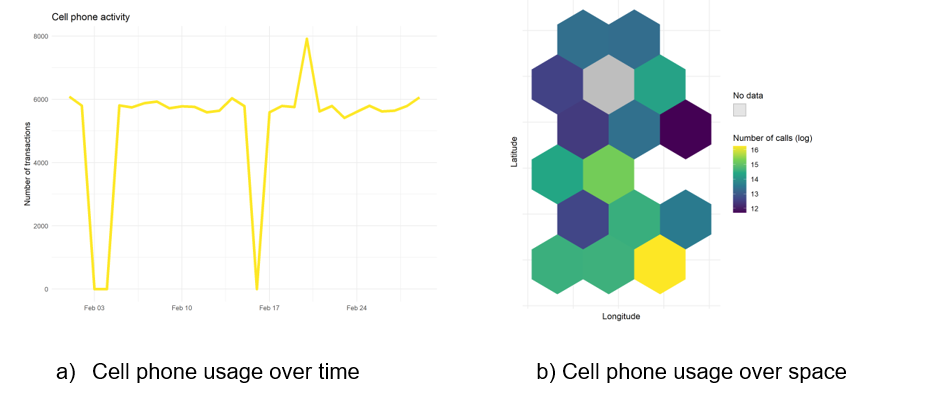
Consistency
How to: In the survey context, check whether responses across different modules align. For example, it would be internally inconsistent for a farmer to report having farmed 1 hectare of maize but harvested 20 tons of maize. In the big data context, check whether values across variables align with each other and with expectations. In both survey and big data contexts, this type of check follows the same two steps. Before the data is acquired, look for auxiliary data that can help define benchmark value ranges. Once the data is received, check whether values across variables in the acquired dataset align among themselves, and whether they fall within the expected ranges. What exact checks to run will vary widely from one project to another, and the number of possible tests grows quickly with the number of variables included. So it is important to list and prioritize as early as possible, preferably before receiving the data.
Example: Figure 3 shows two examples of consistency checks. Panel (a) checks that the number of daily transactions (calls, SMS, etc.) is consistent with the number of users in aggregated cell phone data. Points in purple are problematic entries since every transaction must have at least one user who originates it. Panel (b) displays a check for pollution sensors, comparing the values obtained for the same area and time by two different sensors. Points in purple are problematic as the sensors should generate similar measures.
Figure 3 - Consistency checks

Anomalous Data Points
How to: In the survey context, this is typically controlled through careful electronic survey programming by setting accepted values for each question. In the big data context, there is a high likelihood of outlier observations that may occur due to random events that can affect the data collection process. As with completeness, visualizing the data is an effective way to identify anomalies. Often there are numerous spikes, some low and some high. How do we define which ones are anomalies? A simple way is to use standard deviation as a benchmark, which can work no matter what data you work with. After calculating the mean for the variable of interest over time, flag observations that are 2 standard deviations higher or lower. As with survey data, these flags serve to identify observations that should be checked and not necessarily that are incorrect. Researching the context around the flags that are seen is important to separate real behavioral changes from data quality issues.
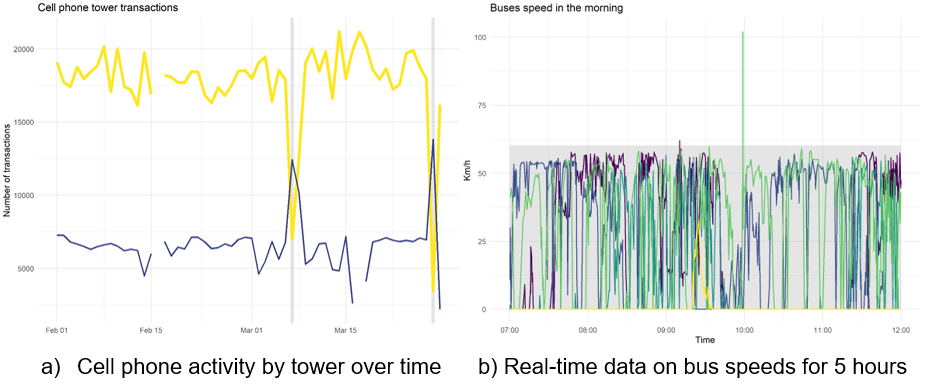
Examples: Figure 4 shows two examples where anomalies were detected in the data. Panel (a) shows how tower outages (in gray) were identified in cell phone data: the usage of the tower that is down decreases drastically (yellow line), and a neighboring tower (purple line) picks up the traffic, leading to a spike in the number of transactions. Panel (b) shows the speed of 4 vehicles over time. The gray area marks the cutoff of 2 standard deviations, so anomalous data points can be easily spotted.
Figure 4 - Data points checks
Real-Time
How to: In the survey context, it will be much easier to discuss and resolve data issues with the survey firm in the hours and days after surveys are completed, as enumerators are more likely to remember interviews and revisits are simpler when teams are still in the local area. In the big data context, “revisits” are often not an option, but it is also true that the sooner issues are identified, the more likely they are to be fixed, particularly when the data is incomplete. As time passes, the person familiar with the database may leave the data provider, or it may cease operating altogether; the code for data extraction or aggregation may be deleted by the counterpart that wrote it; the website that was scraped may change or be taken offline; servers may have been wiped. The list gets longer the more time passes. For these reasons, the simple checks discussed in the previous three points should be set to run daily. Flagging issues and discussing those in real-time with the data provider will lead to faster resolution and higher quality data.
Examples: After setting up a microsensor to collect air quality data, our team checked the data coming in every day. One day we saw that no data was collected. Upon checking the sensor in person, it was discovered that after a power outage, the sensor did not properly begin collecting data again, and it was necessary to reset. Only one day of data was lost—as opposed to weeks if data checks had been done less frequently.
To summarize, don’t assume that big and real-time datasets are necessarily high quality. Responsible data use requires opening the black box and scrutinizing the data before using it for research. By following the simple principles outlined above, researchers can ensure that they put real-time data and big data through the same rigorous quality control process as survey data, improving the accuracy of the data and the credibility of research findings.
Acknowledgments:
The research has been possible thanks to UK aid from the UK government through the i2i and ieConnect for Impact programs; support from the Trust Fund for Statistical Capacity Building III (TFSCB-III), which is funded by the United Kingdom’s Foreign, Commonwealth & Development Office, the Department of Foreign Affairs and Trade of Ireland, and the Governments of Canada and Korea; as well as support from the Research Support Budget in the Development Economics Vice-Presidency.
[1] The examples included in the checks below are all based on real data use cases at DIME, but use simulated versions of the data to comply with data use agreements.




Join the Conversation