AI can do almost anything these days, it seems: format your bibliography, write your job ad, or coauthor your paper. Sometimes, of course, it hallucinates outrageous answers to questions. But can it code? I tried asking OpenAI’s ChatGPT for six pieces of Stata code (with one of them in some other languages as well), and results were… mixed. It gets some easy questions right, and sometimes it can suggest useful (if broken) prototype code. In spite of all the hype, you aren’t about to hire ChatGPT as your next research assistant.
First, an easy graph formatting question: how to change the x-axis labeling on a graph. ChatGPT aces it.
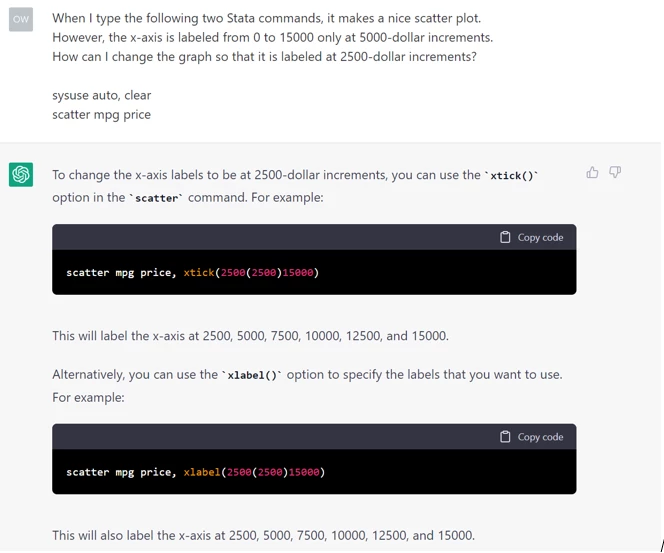
As shown in the image, with my text at the top and ChatGPT’s response afterward, ChatGPT improves the graph as desired, with two options, both of which mark the axis at the desired interval, though only one labels the tick marks with the associated numbers. Not bad so far. ChatGPT 1, Human 0.
Second, I asked “How do I make Stata's random number generator generate the same sequence of random numbers twice in a row, for code replicability?” ChatGPT gave a correct response (set seed), but then followed up with a code snippet that did not work because of a mistake in the “foreach” syntax. It took several rounds of suggestions before ChatGPT suggested a code snippet that worked. At least the first part was right. Call that a draw. ChatGPT still in the lead, 1-0.
Third, I asked about the summarize command. When I summarize car prices in the default automobile dataset, it shows three places after the decimal. I asked ChatGPT how to get a fourth decimal place, and how to get the variance without any additional calculation. Eventually it came up with good answers to these questions, but it involved several rounds of back-and-forth chat. The incorrect suggestions included its first big hallucination: ChatGPT invented a Stata “pwvariance” function that I believe is entirely fictitious. But eventually, with heavy coaching, ChatGPT hit on a solution that worked. ChatGPT loses this round, so it’s tied 1-1.
Fourth, I asked for a Stata command, besides “duplicates list,” that might tell me whether an identifier uniquely identifies the observations in a dataset. A quick Google search brings up IPA’s suggested answer to this question, but I couldn’t coax ChatGPT to come up with this answer. It did suggest something wacky that wouldn’t work: “tabulate, nodup,” which appears to be a blend of SAS and Stata syntax. For the back-to-back hallucinations, ChatGPT is now behind, 1-2.
Fifth, at David McKenzie’s suggestion, I asked ChatGPT to translate some pretty standard “econ-speak” into a regression command. I asked it, “I am doing data analysis in Stata using the built-in 1978 automobile dataset. I want to regress car weight on a treatment indicator for being foreign, controlling for length and repair record fixed effects, and then cluster standard errors at the brand level. What command should I use?” It had to guess at variable names, but with that adjustment it came up with:
xtreg weight i.foreign##c.length c.rep78, re i(brand) cluster(brand)
This is not correct. It has added an interaction between foreign and length (not requested), and has not included length and repair record fixed effects, instead treating them as continuous regressors. ChatGPT needs some pretty hands-on micromanagement! A better answer would have been:
reg weight i.foreign i.length i.rep78, cluster(brand)
Or, recognizing that the first regressor is already a dummy variable, any of the three commands below (as well as other possibilities) would have been a good answer:
reg weight foreign i.length i.rep78, cluster(brand)
areg weight foreign i.rep78, absorb(length) cluster(brand)
reghdfe weight foreign, absorb(length rep78) vce(cluster brand)
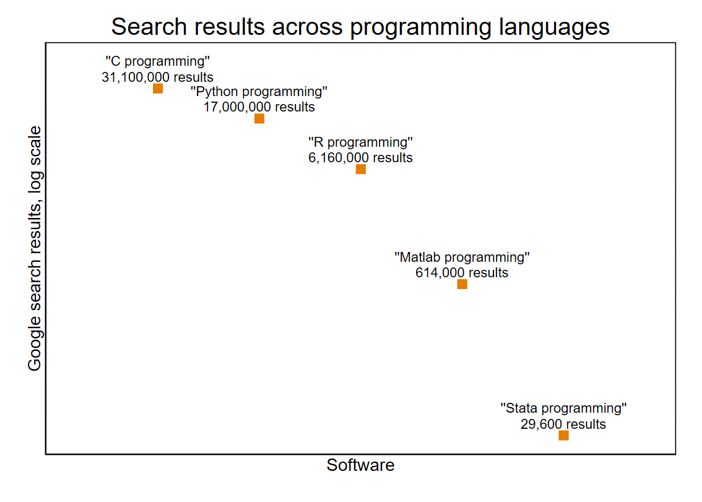
Finally, with ChatGPT trailing 1-3, I tried something tricky. I asked for Stata code that would produce Fibonacci numbers using a recursively defined function. ChatGPT outlined a couple of pieces of what appeared to be Stata code, but it couldn’t get the syntax completely right for local macros and r-class Stata programs; neither of the approaches ChatGPT suggested worked without some fixes. I wondered if this was simply too hard of a task in general, so I asked ChatGPT for the same sort of function in R, Python, Matlab, and C. In each of the other four languages, ChatGPT provided code that worked the first time. There are many reasons why this might be. One is that this isn’t really the kind of thing people use Stata to do, or that it is mainly designed for, so while it is possible, it is not a standard or efficient way to program in Stata. Maybe it wasn’t a fair challenge, so I won’t update the scoreboard. Another possible factor is the relative availability of advice on the internet, since the internet is the source of the text on which ChatGPT was trained. The graph below shows the relative availability of advice on “Stata programming” relative to, for example, “C programming,” as seen via the number of total Google search results for those phrases: Stata has an order of magnitude fewer search results than Matlab, and is further behind Python, R, and C (though Google searches for one-letter strings may produce some measurement error).
Overall, what I found is consistent with a concern that others have voiced that ChatGPT’s answers to computer programming questions “have a high rate of being incorrect.” This may be good news for the continued existence of take-home interview questions involving Stata (though it might be a warning for those giving take-home tests involving R). The code ChatGPT generates might help an experienced programmer get started, but ChatGPT’s hallucinations could be hard for a novice to micromanage away. In short, research assistants won’t be out of a job just yet. Stata programming is safe from an AI takeover… for now.

Join the Conversation