A nice new
paper by Abhijit Banerjee, Sylvain Chassang, and Erik Snowberg brings theory to how we choose to do evaluations – with some interesting insights into those of us who do them. It’s elegantly written, and full of interesting examples and thought experiments – well worth a read beyond the injustice I will do it here.
The basic theoretical idea here is that we (folks who do experiments) are individually Bayesian and collectively ambiguity adverse. The model explains this clearly, but let me take a stab with some words. Take the case they use, of an education official trying to decide whether to do vouchers. She has a prior that family background is all that matters for educational outcomes. She has the chance to send one kid from a disadvantaged background to a private school (where outcomes are better in this community). Very informative with respect to her priors. And now add a privileged kid. She would learn a lot by sending the privileged kid to a public school. Here, an experiment with a sample size of 2 and deterministic assignment can be hugely informative. So in this world, randomization of the school isn’t optimal since it’s all about addressing the prior beliefs she has.
Now suppose that she has to make her decision in consultation with others (or to convince an audience), with other prior beliefs (e.g. that privileged kids won’t fare well in public schools). Deterministic assignment gets progressively more difficult. In the end, as Banerjee and co. put it: “randomized experiments emerge as the only ones that successfully defend against all priors, that is the only experiments whose interpretation cannot be challenged even by a devil’s advocate.”
This line of reasoning leads us to the following picture – where the more we need to convince a group of skeptics with varying priors (robustness) and the potential sample size determine when randomization is the optimal course of action:
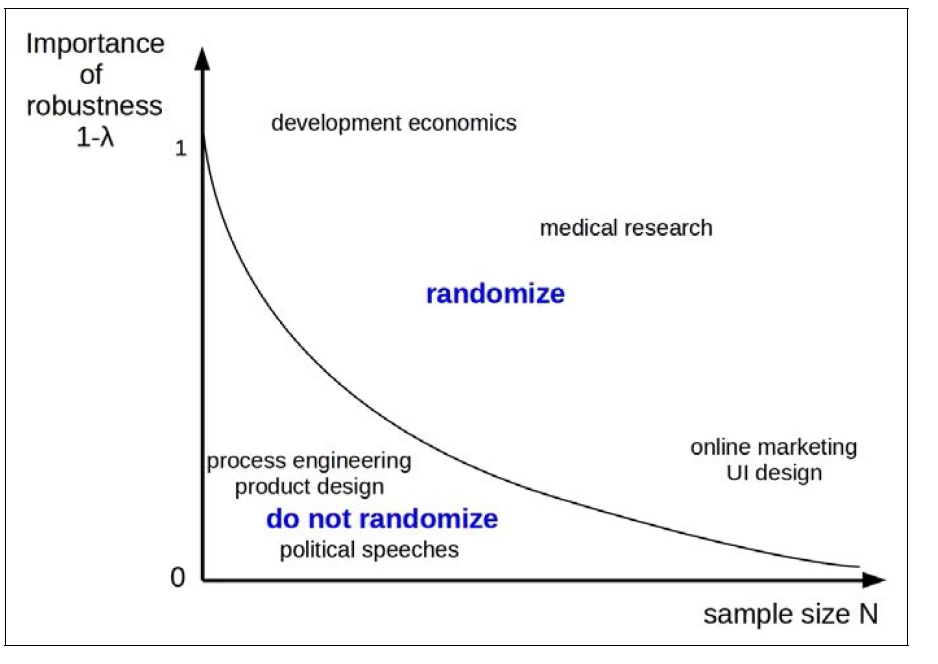
This argument (plus the worked out model) then leads into a number of implications for how we do our work:
1. Re-randomizing might be ok. So you draw your sample and it’s not balanced. What to do? More often than we talk about, folks go back for a second draw. Banerjee and co. point out that for the non-Bayesian, re-randomization will result in some losses. But they argue that for a small number of re-randomizations, this is outweighed by the gains. Their rule of thumb: “Use the most balanced sample of K randomizations, where K=min{N, 100}.” Keep in mind that N is the number of clusters. And one interesting extension: in some cases it might be good to let the program folks choose from among a set of randomized draws.
2. Registration: the good. Registration of trials is unambiguously good in the sense that it gives us more information about what research is happening. Things get a bit more ambiguous when we turn to the fact that registration also commits you to a particular research plan. This can be good, in that it establishes an agreement between the experimenter and her adversarial audience that makes reneging hard, if not impossible. But…
3. Registration: the bad. The bad part of commitment comes when it ties the experimenter’s hands and prevents useful updating. None of us can foresee all possibilities and if we can’t adjust we’ll end up completing some dumb(er) experiments some fraction of the time. Indeed, Banerjee and co. give a number of examples (in which at least one of them is implicated) where registration tied the hands of researchers and limited what they could do (in a counterproductive way).
4. Pre-analysis plans. “Interestingly, neither Bayseian nor ambiguity-averse decision makers find it beneficial to register a pre-analysis plan, nor would her audience care if she did. This follows from two implicit assumptions: 1) all data is disclosed, and 2) the decision maker and audience members have unbounded cognitive capacity. If an audience member is suspicious that the experiment cherry-picked results, she can just run her own analyses.” Alas, as Banerjee and co. point out, people can only process so much information. So while a scholarly audience might be happy just demanding a set of robustness checks (as they did in the old days), policymakers may prefer to update only from simple, clear pre-analysis plans. The solution they propose – in order to avoid losing valuable but unforeseen analyses – is to separate out ex ante specified analysis and the ex post and make this distinction clear in the narrative.
5. External validity: legalizing speculation. Banerjee and co. point out that “external policy advice is unavoidably subjective. This does not mean that it needs to be uninformed by experimental evidence, rather, judgement will unavoidably color it.” So, the trick is to get experimenters to lay out their honest beliefs about what might work where. Banerjee and co. lay out the idea of “structured speculation”, which is speculation that is clearly identified as such, contains systematic speculation about external validity, and that is precise and falsifiable. The last criteria helps in avoiding idle speculation, since I go on the record as speculating that this intervention would work in these kinds of settings, or would have higher impacts for these kind of people. The big bonus in this approach is that it will ultimately influence the design of the experiment, for example by pushing us ex ante to think harder about the dimensions of heterogeneity that are important to capture and analyze.
Banerjee and co. argue that four dimensions of external validity are of particular importance:
I think this paper gives us a lot to think about and a neat way to think about it -- it’s a theory paper that kind of makes you feel like you are going through therapy while you are reading it. One fundamental concern I have is that Banerjee and co. are trying to shift the evolving norms of the economics profession (e.g the pursuit of the scientific standards (if not the behavior) we see in medicine). Given that publication remains one of the most (if not the most) central metrics of the profession, I am worried that their approach will afoul of a less desirable equilibrium.
Take two dimensions: pre-analysis plans and the speculation on external validity, both of which have been both subjects of recent discussions I have had with colleagues on their less-than-smooth publishing experiences. On pre-analysis plans, if referees take only the work specified in the pre-analysis plan as valid and disregard anything else, we will cut off a serious avenue for some creative, useful work. On speculation, a common refrain among development economists is that their work is rejected from top journals because it is “not of general interest.” Part of this lack of general interest is straight geographical discrimination, as my colleagues Jishnu Das and Toan Do argue in this post (and related paper). So if we add to this developing country publishing disadvantage some structured speculation as to what other (developing country) populations these results could apply to, we could be exacerbating the bias that Das and Do document (e.g. by reminding the referee that we are writing about a conflict-affected small sub-Saharan African nation).
Maybe this is an unfounded concern. The world that Banerjee and co. lay out is an exciting one, with clear paths to better knowledge. Here’s hoping we get there.
The basic theoretical idea here is that we (folks who do experiments) are individually Bayesian and collectively ambiguity adverse. The model explains this clearly, but let me take a stab with some words. Take the case they use, of an education official trying to decide whether to do vouchers. She has a prior that family background is all that matters for educational outcomes. She has the chance to send one kid from a disadvantaged background to a private school (where outcomes are better in this community). Very informative with respect to her priors. And now add a privileged kid. She would learn a lot by sending the privileged kid to a public school. Here, an experiment with a sample size of 2 and deterministic assignment can be hugely informative. So in this world, randomization of the school isn’t optimal since it’s all about addressing the prior beliefs she has.
Now suppose that she has to make her decision in consultation with others (or to convince an audience), with other prior beliefs (e.g. that privileged kids won’t fare well in public schools). Deterministic assignment gets progressively more difficult. In the end, as Banerjee and co. put it: “randomized experiments emerge as the only ones that successfully defend against all priors, that is the only experiments whose interpretation cannot be challenged even by a devil’s advocate.”
This line of reasoning leads us to the following picture – where the more we need to convince a group of skeptics with varying priors (robustness) and the potential sample size determine when randomization is the optimal course of action:
This argument (plus the worked out model) then leads into a number of implications for how we do our work:
1. Re-randomizing might be ok. So you draw your sample and it’s not balanced. What to do? More often than we talk about, folks go back for a second draw. Banerjee and co. point out that for the non-Bayesian, re-randomization will result in some losses. But they argue that for a small number of re-randomizations, this is outweighed by the gains. Their rule of thumb: “Use the most balanced sample of K randomizations, where K=min{N, 100}.” Keep in mind that N is the number of clusters. And one interesting extension: in some cases it might be good to let the program folks choose from among a set of randomized draws.
2. Registration: the good. Registration of trials is unambiguously good in the sense that it gives us more information about what research is happening. Things get a bit more ambiguous when we turn to the fact that registration also commits you to a particular research plan. This can be good, in that it establishes an agreement between the experimenter and her adversarial audience that makes reneging hard, if not impossible. But…
3. Registration: the bad. The bad part of commitment comes when it ties the experimenter’s hands and prevents useful updating. None of us can foresee all possibilities and if we can’t adjust we’ll end up completing some dumb(er) experiments some fraction of the time. Indeed, Banerjee and co. give a number of examples (in which at least one of them is implicated) where registration tied the hands of researchers and limited what they could do (in a counterproductive way).
4. Pre-analysis plans. “Interestingly, neither Bayseian nor ambiguity-averse decision makers find it beneficial to register a pre-analysis plan, nor would her audience care if she did. This follows from two implicit assumptions: 1) all data is disclosed, and 2) the decision maker and audience members have unbounded cognitive capacity. If an audience member is suspicious that the experiment cherry-picked results, she can just run her own analyses.” Alas, as Banerjee and co. point out, people can only process so much information. So while a scholarly audience might be happy just demanding a set of robustness checks (as they did in the old days), policymakers may prefer to update only from simple, clear pre-analysis plans. The solution they propose – in order to avoid losing valuable but unforeseen analyses – is to separate out ex ante specified analysis and the ex post and make this distinction clear in the narrative.
5. External validity: legalizing speculation. Banerjee and co. point out that “external policy advice is unavoidably subjective. This does not mean that it needs to be uninformed by experimental evidence, rather, judgement will unavoidably color it.” So, the trick is to get experimenters to lay out their honest beliefs about what might work where. Banerjee and co. lay out the idea of “structured speculation”, which is speculation that is clearly identified as such, contains systematic speculation about external validity, and that is precise and falsifiable. The last criteria helps in avoiding idle speculation, since I go on the record as speculating that this intervention would work in these kinds of settings, or would have higher impacts for these kind of people. The big bonus in this approach is that it will ultimately influence the design of the experiment, for example by pushing us ex ante to think harder about the dimensions of heterogeneity that are important to capture and analyze.
Banerjee and co. argue that four dimensions of external validity are of particular importance:
- “How scalable is the intervention?
- What are the treatment effects on a different population?
- What are treatment effects on the same population in different circumstances?
- What is the effect of a different, but related, technology?”
I think this paper gives us a lot to think about and a neat way to think about it -- it’s a theory paper that kind of makes you feel like you are going through therapy while you are reading it. One fundamental concern I have is that Banerjee and co. are trying to shift the evolving norms of the economics profession (e.g the pursuit of the scientific standards (if not the behavior) we see in medicine). Given that publication remains one of the most (if not the most) central metrics of the profession, I am worried that their approach will afoul of a less desirable equilibrium.
Take two dimensions: pre-analysis plans and the speculation on external validity, both of which have been both subjects of recent discussions I have had with colleagues on their less-than-smooth publishing experiences. On pre-analysis plans, if referees take only the work specified in the pre-analysis plan as valid and disregard anything else, we will cut off a serious avenue for some creative, useful work. On speculation, a common refrain among development economists is that their work is rejected from top journals because it is “not of general interest.” Part of this lack of general interest is straight geographical discrimination, as my colleagues Jishnu Das and Toan Do argue in this post (and related paper). So if we add to this developing country publishing disadvantage some structured speculation as to what other (developing country) populations these results could apply to, we could be exacerbating the bias that Das and Do document (e.g. by reminding the referee that we are writing about a conflict-affected small sub-Saharan African nation).
Maybe this is an unfounded concern. The world that Banerjee and co. lay out is an exciting one, with clear paths to better knowledge. Here’s hoping we get there.

Join the Conversation