Amazon.com started as just a guy selling books out of a garage in Seattle and took nine years to make a profit. As it expanded to reach more customers it was able to hire specialists, increase the variety of products, take advantage of economies of scale, and benefit from network externalities. All of these factors make it a much more effective and productive large company than it was as a small company.
This idea that larger is better and more productive is in stark contrast to what we see with the results of many impact evaluations of social programs. Indeed, Peter Rossi famously coined his Iron Law of Evaluation “The expected value of any net impact assessment of any large scale social program is zero”. This contrast between what we expect from big firms versus big programs came to mind again when I saw Dave Evans tweet the figure below, from a paper by Caridad Araujo, Marta Rubio-Codina and Norbert Schady with the great title of “70 to 700 to 70,000: Lessons from the Jamaica experiment”.
The Jamaica experiment and taking it to scale
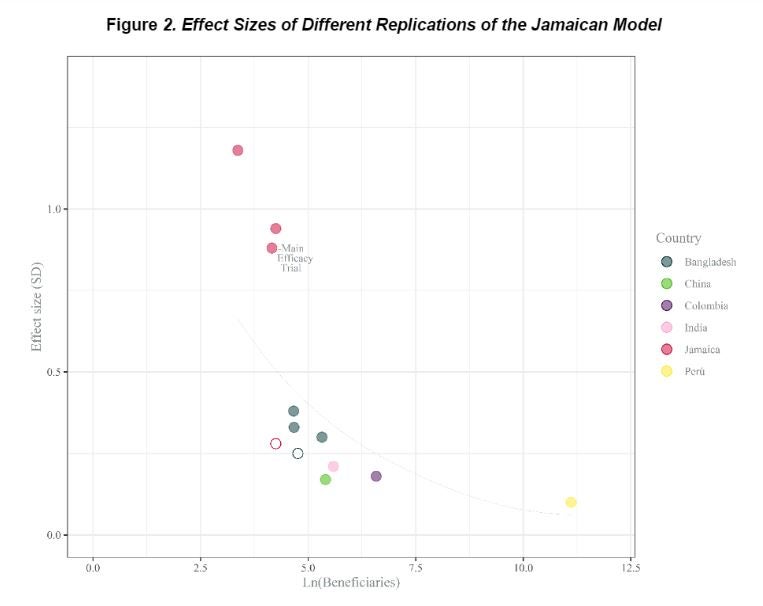
The starting point here is a program implemented in Kingston, Jamaica in the mid-1980s, which aimed to improve development outcomes for malnourished young (9-24 month old) children through regular home visits from community health workers. These visits were play-based, aimed at promoting caregiver-child interactions, and were accompanied with low-cost blocks, toys, puzzles, and books to stimulate this play. The initial RCT was with 129 children allocated into four groups, with 64 receiving the home visits. This led to a 0.88 S.D. impact on overall child development after 24 months of visits, and appears as the solid red dot on the figure above (ln of 64 = 4.16 on the x-axis, and 0.88 on the y-axis). Part of the reason this study is so famous is that the children have been followed into adulthood, and over 20 years after the program had ended, those randomly assigned to treatment had more schooling, higher test scores, higher employment, and higher wages than the control group.
The paper notes that an adaptation of this model was implemented as a pilot in Colombia in 2010-11, with about 720 children (6.58 on the log scale) receiving home visits, and impacts of 0.18 to 0.26 S.D. on various development measures (the solid purple dot), and implemented at scale in Peru reaching 67,332 children in 2015 (11.1 on the log scale), with an impact of 0.1 S.D. on an index of child development (the solid yellow dot at the bottom right of the figure). They also include in the figure several other studies based on this model, with non-solid circles denoting not statistically significant results.
The pattern in this figure shows a stark drop in effect size as the program scales up – as the authors note, moving from “70 to 700” (Jamaica to Colombia) sees the impact fall by four-fifths, and it falls further as one goes from “700 to 70,000” (Colombia to Peru).
Why does impact fall with scale?
The authors follow a framework set out in a paper by Al-Ubaydli, List and Suskind of issues involved in scaling experiments to attempt to understand why the impacts fall with scale. They consider three reasons:
· Statistical inference: the concern here is that this program only was scaled up because the initial estimates were statistically significant, but this might have just reflected a lucky draw in a small sample. As Andrew Gelman notes “when samples are small and measurements are noisy, any statistically significant estimates will be necessarily “substantial,” as that’s what it takes for them to be at least two standard deviations from zero.” Or as Al-Ubaydli et al. put it, there tends to be a winners-curse effect, where only scaling up studies from small samples that have the largest and most statistically significant effects leads to a magnitude overstatement bias. The authors note that one piece of evidence against this concern in the case of these home-visit interventions is that there were in fact three other replications in Jamaica with similar sample sizes, two of which had even larger effects (0.94 and 1.1S.D) and one with a statistically insignificant effect (0.28 S.D.) – all shown in the figure above. Instead they note a different measurement concern – that the scale used to measure child development may have been more sensitive to the intervention in Jamaica than scales used elsewhere.
I’ll note here another statistical inference issue we have previously noted: when comparing studies on the basis of standard deviations, since larger samples tend to be more heterogeneous and have larger variances, this will by itself cause the same absolute effect size to fall with sample size when converted to S.D. units.
· Representativeness of the population: this issue relates to targeting and whether pilot programs target on participants who might be expected to benefit most from the intervention, and so scaling up involves offering the program to less disadvantaged children or families that would benefit less from the intervention. This is what Hunt Alcott found in his work on energy conservation scale-up, where the energy utility initially targets areas with bigger treatment effects. The authors note that the Jamaican children were more malnourished and poorer than those in Colombia, which might explain part of the difference in scaling there, but that studies in Bangladesh and India were with, if anything, even more disadvantaged children, and yet the figure shows impacts were much lower than the Jamaican ones there. However, they do note that the Jamaica study is vague on whether participants were screened for interest and whether those who didn’t want the program replaced, whereas in Colombia and Peru not everyone took up the program, so comparing ITTs across studies is affected by different non-complier rates. Of course non-compliance itself is a function of scale- it is easier to spend time explaining the program and chasing up those who don’t want it with 64 kids than with 64,000 – in Peru one-third of the children didn’t take up the program.
· Representativeness of the situation: the issue here is that the way programs are implemented changes with scale. For example, small “proof-of-concept” trials are usually carefully overseen by researchers with strong incentives for making everything go right, while larger trials may be implemented by government workers who have many other priorities. As another example, when you just need to hire enough health workers to visit 64 households, you can screen and choose the very best ones, but when you are having to serve thousands you can’t be so picky. The researchers point to this as one potential explanation here – in Jamaica the home visit workers were much more closely supervised and mentored, and researchers who had designed the materials were much more involved in implementing it. They note this was even more of an issue when going to scale in Peru – there were not enough people that met the technical qualifications to be home visitors, so they had to lower the education requirements. They also note the usual bureaucratic constraints involved in scaling up – government procurement and payment delays meant manuals and toys were slow to get disbursed, and some visits had to take place before these were ready.
The other key factor with scale is that the dosage often falls – it becomes harder to deliver the same intensity of treatment. The authors note that in Colombia, 97% of households took it up, and those taking it up received 81% of planned visits, whereas in scaled-up Peru, only 50% of planned visits took place for the 66% taking it up – so the effective dosage was 79% in Colombia vs 32% in Peru. This is another reason for the ITT to fall.
How iron is the iron-law, or when might impacts rise with scale?
So, are we always doomed to see less impacts as programs scale? I think the benefits of many human-capital intensive interventions like these home visits, mentoring and training programs, etc. are often going to fall with scale for the targeting and implementation reasons noted above. However, the costs of providing these services may also fall with scale as the costs of content development and other fixed costs get spread over more users, so the cost-effectiveness of the program could remain similar or even increase even if benefits are falling.
But there are many other types of interventions which look a lot more like the Amazon.com example, where it is hard to do it effectively in a small pilot, and may need scale and network effects to make it work better. A number of the projects I’ve worked on have (frustratingly) had this flavor – for example, trying to shorten supply chains between farmers and vendors is likely to work better if you have many more customers to spread costs over and make it worth offering lots of products; developing a new marketplace for professional business services seems like it would work better with a thicker marketplace where reputations matter more and there is more customer feedback; a new commitment product to enable migrants to directly pay for education fees in their home country would likely work better if there were many schools and many migrants using it; a recruitment platform for migrants needs lots of employers and migrants to enable job matches to be found, etc. These types of interventions are really hard to pilot at smaller scales, but as the Amazon example of nine years before profitability illustrates, it can also take a long time and a lot of faith and money to build big. And, of course, we then also need to start worrying about other at-scale effects like spillover impacts/general equilibrium effects…

Join the Conversation