This is the first in our series of posts by students on the job market this year.
Impact evaluations are often used to justify policy, yet there is reason to suspect that the results of a particular intervention will vary across different contexts. The extent to which results vary has been a very contentious question (e.g. Deaton 2010; Bold et al. 2013; Pritchett and Sandefur 2014), and in my job market paper I address it using a large, unique data set of impact evaluation results.
I gathered these data through AidGrade, a non-profit research organization I founded in 2012 that collects data from academic studies in the process of conducting meta-analyses. Data from meta-analyses are the ideal data with which to answer the generalizability question, as they are designed to synthesize the literature on a topic, involving a lengthy search and screening process. The data set currently comprises 20 types of interventions, such as conditional cash transfers (CCTs) and deworming programs, gathered in the same way, double-coded and reconciled by a third coder. There are presently about 600 papers in the database, including both randomized controlled trials and studies using quasi-experimental methods, as well as both published and working papers. Last year, I wrote a blog post for Development Impact based on this data, discussing what isn't reported in impact evaluations.
Since we are interested in looking at how much results vary within a particular intervention-outcome combination (for example, the effect of school meals on test scores), the definition of the intervention and the outcome is very important. AidGrade used three different coding rules for the outcome, the strictest being quite specific, such as "height in centimeters". A little less than half the papers on a particular intervention shared a narrow outcome in common, and it is this set on which I base the paper. Characteristics of the interventions were coded, such as how much money was given in conditional cash transfer programs, but these were generally too sparse to use.
In the paper, I do several things, such as conducting leave-one-out hierarchical Bayesian meta-analyses within each intervention-outcome combination and seeing how well the result predicts the one that was left out. I also devote a lot of attention to biases that might creep in, such as publication bias and specification searching (whereby researchers might run many regressions and only report the significant ones). I find surprisingly little evidence of bias, particularly for randomized controlled trials (RCTs), which appear to be less biased than studies using quasi-experimental methods.
The paper goes into more detail, but for this blog post I will focus on some easily interpretable summary statistics that answer the question: how much do impact evaluation results vary? In particular, I will look at two measures: 1) the percent of results' confidence intervals that overlap within an intervention-outcome combination; 2) the typical gap between a study's findings and the average finding within that intervention-outcome combination.
1) What percent of results' confidence intervals overlap within an intervention-outcome combination?
This is useful to know as when they do not overlap they are clearly different.
On average, a given result in an intervention-outcome combination will have a confidence interval that overlaps with 3/4ths of the confidence intervals of the other results in that intervention-outcome. The point estimate will be contained in the confidence interval of the other studies approximately 2/3rds of the time.
Given that the interventions were somewhat heterogeneous, even apart from having been done in different contexts, this is perhaps a higher share than one might have expected. However, it is also a function of the confidence intervals; there will be more overlap when the confidence intervals are large. Thus, apart from looking at the confidence intervals, I also look at the point estimates.
2) What is the typical gap between a study's point estimate and the average point estimate within that intervention-outcome combination?
These differences in point estimates are perhaps the most easily interpretable. The mean gap is about 80%, with the median gap a little less than 50%. The table below expresses this in absolute terms for each intervention-outcome combination covered by at least three papers.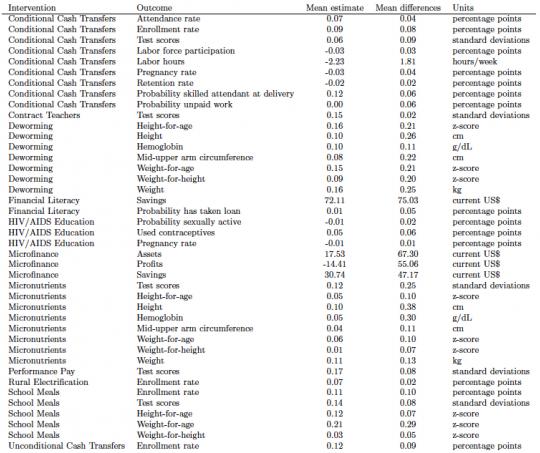
The mean difference between a given study's results and the mean within that intervention-outcome is often greater than the difference between the mean result and the null hypothesis of zero effect.
Given that different programs were quite different, we should expect variation in results. In fact, it is perhaps surprising that when I generate the leave-one-out hierarchical Bayesian meta-analysis results in the paper and regress the result left out on this predictor, the coefficient is as high as 0.6-0.7 after correcting for attenuation bias. A perfect fit would have a coefficient of 1. The R^2 for this regression is quite low, however.
Again, this is only one slice of the overall paper, but it is very relevant if we are to extrapolate from one context to another in designing policy. In the greater paper, I also find that when academics or NGOs implement a project, the project tends to yield higher effect sizes than when a government implements it; worrisome if the smaller, academic/NGO-implemented projects are intended to estimate the effects of the program were the government to implement it on a larger scale.

Join the Conversation