
The effect of time of day on mood via the Jawbone Blog
Here are some things that caught our attention last week:
-
There’s a consultation draft of the International Open Data Charter up for… consultation. It outlines a set of principles for accessing and using open data which are:
- Open Data by Default;
- Quality and Quantity;
- Accessible and Useable by All;
- Engagement and Empowerment of Citizens;
- Collaboration for Development and Innovation;
- My friend David MacIver is many things, but for readers of this post, he’s the author of Hypothesis. It’s a Python library that makes unit testing simpler and substantially more powerful by automating test case generation, using the concept of “property based testing” as Matt Bachmann outlines in his useful post.
-
Pivot Tables are useful data summarization tools that most Excel users will be familiar with. Chris Moffitt wrote a great post on “Pandas Pivot Table Explained” which in addition to being a good tutorial, offers a handy cheat sheet for folks wanting to make pivot tables in Python with Pandas.
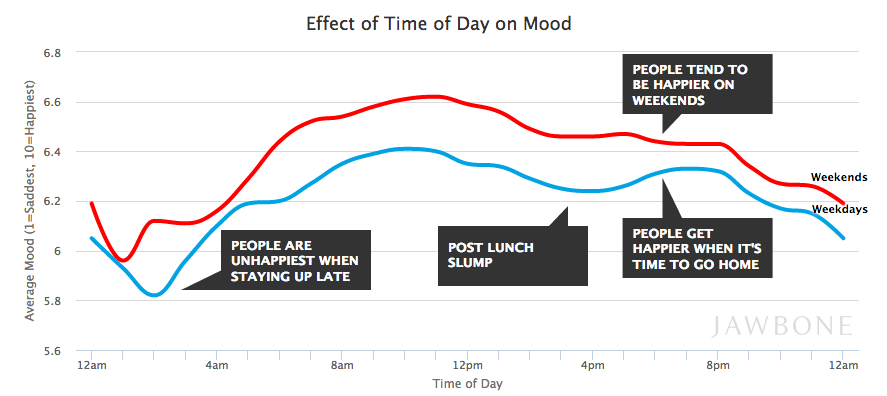
- It’s often fun to read the “data lab” blogs of companies that collect or produce devices that collect a lot of data. Jawbone took data on “hundreds of thousands” of users of their app tracking their sleep and mood and attempted to answer: “What makes people happy?”
-
Finally, do you ever find yourself having coffee with a data scientist feeling lost as they harp on about “k-means”, “C4.5” and their “support vector machines”. Well, Ray Li has you covered, check out his “Top 10 Data Mining Algorithms in Plain English”

Join the Conversation