Like many readers of this blog, I was over the moon about this year's Nobel Prize in Economics, awarded to Abhijit Banerjee, Esther Duflo, and Michael Kremer "for their experimental approach to alleviating global poverty." As David wrote the day of the announcement, randomized control trials (RCTs) have fundamentally changed the way we do research. The research implemented and inspired by the winners, as some journalists have noted (NPR and NYTimes), has also changed our understanding of the constraints that poor people face around the world.
I think we should also acknowledge just how much this kind of experimentation has influenced policy. By this, I do not have in mind only the successes of the type that the Nobel Committee mentioned in their press release, where estimated treatment effects have justified the scaling of effective programs (tutoring or teaching to the right level) or reinstating policies that had fallen from favor (subsidies for preventive health care). The movement of experimentally testing potential policies has inspired a number of programs at the World Bank like the Development Impact Evaluation group (DIME); the regional Gender Innovation Labs (Africa, Latin America and Caribbean, Middle East and North Africa, East Asia and Pacific, and South Asia); and the Strategic Impact Evaluation Fund (SIEF), and all of these programs predominantly fund RCTs of government reforms. From these experiences, we see that the policy footprint of these kinds of experiments - their total impact on public policy – can encompass much more than scaling and cancelling programs.
In the SIEF portfolio, which I manage, these efforts have led to direct impacts like those mentioned by the Nobel committee, where evidence has underpinned the rationale for scaling a program. A trial in Mozambique, for example, led to a national scale-up of community-based preschool. Cash grants to private schools in Pakistan and their estimated impact on school revenues helped convince a private bank to offer loans to schools.
But only looking at cases like this underestimates the size of the policy footprint. We also have many indirect impacts that arise from the process of doing an experiment. Sometimes the careful measurement that goes into an evaluation inspires a government to change the way it does its own monitoring or targeting. For example, after the baseline survey of an experiment in Kenya found large deficits in the quality of care in clinics, the government wrote regulations to incorporate the baseline's indicators and scoring into their national health inspection system. In another experiment estimating the impact of embedding a parenting intervention into a cash transfer program in Niger, the baseline data helped the government identify problems with its targeting mechanism for the cash transfers and other anti-poverty programs. It is important to note that these impacts on monitoring and targeting were not chance by-products of these evaluations; both these teams took time to engage with the government on baseline findings, and I imagine if more researchers deliberately set out to use surveys in this way, the data they collect at baseline could be used for much more than balance tests and increasing the precision of estimated treatment effects.
In other cases, the results from an RCT have spurred iterative experimentation and helped institutionalize a reliance on evidence, even with government partners. In Cambodia, for example, disappointing results from an evaluation of community preschools led to a second experiment testing modifications to the program design (read an interview with one of the researchers, where he talks about moving on from evaluations that don’t show impact). Similarly, an evaluation in Madagascar noted the challenges of scaling up an early nutrition program. These findings led to an experiment testing whether program modifications (like adding door-to-door counseling on early stimulation or lipid-based supplementation for mothers and infants) could improve a range of early childhood development outcomes. The lack of impact of the early stimulation component has in turn influenced the design of another experiment focused on the time-use of community health workers, this time in our nimble portfolio. In both these cases, research teams did not just move on once results were published; they committed to helping a government understand a problem, established trust, and stimulated a demand for evidence.
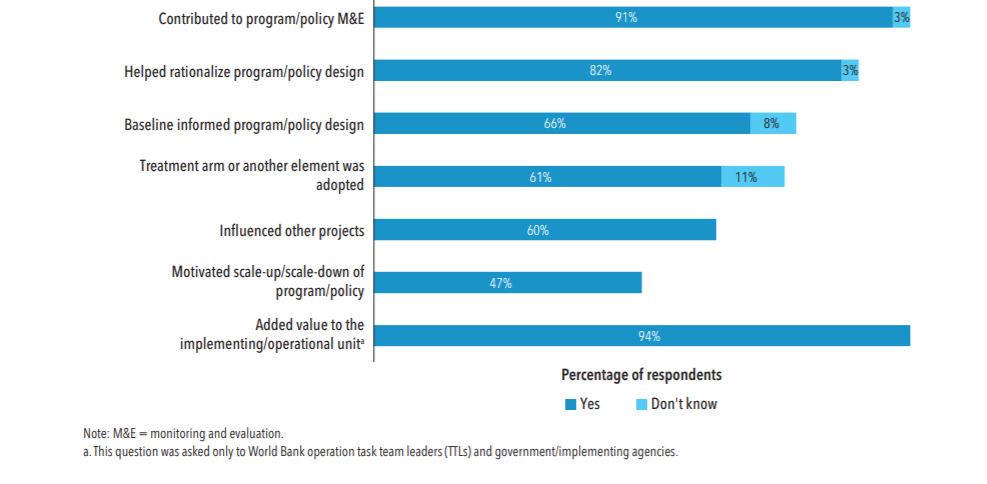
Policy footprints like these are not unique to the SIEF portfolio. In fact, the DIME group has done a survey among researchers, World Bank project leaders, and government officials to quantify how frequently these elements of a policy footprint occur among its evaluations (see chapter 5 of DIME’s latest Annual Report). Survey results from 44 evaluations suggest high influence all around, as you can see from the figure below. Some of their findings, however, also demonstrate how tricky it might be to capture these impacts, as survey respondents did not always agree on what had happened. For example, while 58 percent and 57 percent of government officials and evaluation researchers, respectively, said that evaluation results motivated the scale-up or scale-down of a policy, only 13 percent of project leaders thought that this had occurred. While 82 percent and 94 percent of government officials and project leaders, respectively, agreed that baseline results had informed project design, only 41 percent of evaluation researchers said this happened and another 18 percent said they did not know if this had occurred. In addition to this issue of inter-rater reliability, I myself have found (although I cannot quantify) that intra-rater reliability can also be a problem, as I often never get a sense of policy impact when I ask teams direct questions about it. This information usually comes out when people are explaining something else (like why the project was delayed or why a certain geographic area was over-sampled).
Fraction of respondents to DIME’s survey reporting that an evaluation ….
Further proof that quantifying the policy influence of RCTs can be challenging comes from the portfolio of the Africa Gender Innovation Lab. The lab has put a price on their influence by adding up the monetary value assigned to project components (which are typically part of World Bank lending) that the lab has influenced. The estimated $2.17 billion worth of influence, however, does not reflect the entire policy footprint of the RCTs that the lab funds, as it is difficult to assign a value to all the bad ideas that evidence helped thwart or to the adoption of evidence in the advice provided to governments by other World Bank teams. Similarly, when the Nobel laureates themselves estimate that the innovations funded (and evaluated) by USAID’s Development Innovation Ventures have reached more than 25 million people, this figure reflects those covered by the evaluated interventions and their scale-up versions, not those benefitting from any spillovers to other activities funded by NGOs, governments, or firms.
So what can we do to better document the entire policy footprint of RCTs? This material does not really fit well in research papers, where the focus is on establishing the soundness of an experimental design and presenting estimated treatment effects from that design. Moreover, as we saw from DIME’s survey, researchers may not even be in a position to assess the total footprint of their experiment; we might also require the perspective of consumers of evidence like government officials and project leaders. Perhaps this task must fall to funders of RCTs who have an incentive to track the total return on their investments. If this is the case, then please bear with us, busy researchers and project leaders. Respond to our requests for information throughout the evaluation process. The influence of evidence likely occurs with considerable lag, so we will also need to hear from you even after the research paper or evaluation report has been submitted. Without this information, we will likely underestimate the policy footprint of RCTs and may in turn underinvest in a tool that has the potential to improve welfare on a very large scale.

Join the Conversation