The World Bank’s data catalog curates data from trusted sources to maintain a resource that is both current and accessible to the open data community.
It’s common for data catalogs to include some or all of the datasets that originate in other data catalogs. For example, the World Bank’s Development Data Hub (DDH)—designed to be an efficient “one-stop shop” to obtain data the Bank produces—includes:
- Some datasets from World Bank Group Finances dedicated to financial data;
- Most datasets from the Microdata Library, unit-level data obtained from sample surveys, censuses, and administrative systems and
- A subset of datasets from the Energy data portal.
But how does DDH ensure that it has the latest data and metadata from these different sources? This is where harvesting comes into play.
What is data harvesting?
Data harvesting is a process that copies datasets and their metadata between two or more data catalogs—a critical step in making data useful. It’s similar to the techniques that search engines use to look for, catalog, and index content from different websites to make it searchable in a single location. Application programming interfaces (APIs) act as lines of communication between different databases.
Figure 1 shows how the process of harvesting synchronizes large numbers of datasets between DDH and other data catalogs.
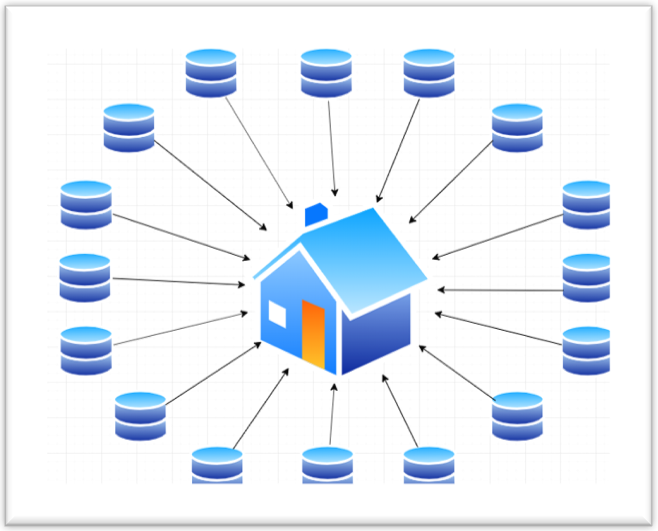
The most important aspect of harvesting, however, is that it happens automatically, in the background, typically on a daily basis, so the data is kept in-sync.
Figure 2 illustrates a dataset harvested from WB Finances, as it appears both in DDH and in its original location. A user can follow the links in DDH to find the original dataset record on its original website:

Benefits of data harvesting
Although harvesting involves many technical elements, such as metadata, APIs, and program scripts, you don’t have to be a technical person to benefit from it. Broad benefits for all users include but are not limited to:
- One-stop shop. Users looking for data can search on the DDH and find information on several different catalogs, without having to search each catalog separately—or even be aware that those catalogs exist.
- Broader exposure. The DDH harvests the metadata and exposes it to a larger audience, so the data that a researcher or data scientist adds to other data catalogs will be exposed to many more users than it would be otherwise.
Technical details for developers
One of the most practical and valuable aspects of the way the DDH Development Group works is that open-source software is used to tackle day-to-day tasks and streamline workflows, while also following best practices in software development so our open-source tools can be used by the public.
You can review the code for one of the DDH harvesters here. In addition, because DDH is built on a DKAN Framework, all DDH harvesters make use of the dkanr package, a World Bank-developed R-Package, which is essential for harvesting.

Join the Conversation