 ESB Professional / Shutterstock.com
ESB Professional / Shutterstock.com
Credit bureaus are essential elements of the financial infrastructure and play a key role in helping to improve access to financial services, including credit. Globally, 65 million enterprises, or 40 percent of formal micro, small and medium businesses in developing countries have unmet financing needs of $5.2 trillion every year. A study using the World Bank’s Enterprise Surveys data from 63 economies and covering more than 75,000 firms found that the introduction of a credit bureau improves firms’ likelihood of access to finance with longer-term loans, lower interest rates, and a higher share of working capital financed by banks (Soledad, Peria and Singh, 2014). The study also found that the greater the coverage of the credit bureau and the scope and accessibility of the credit information, the more profound its impact on firm financing.
According to World Bank data, 117 of 191 economies measured had at least one credit bureau[1] as of May 2019, covering between 1.2 percent and 100 percent of the working age population in each economy. One-third of the economies introduced their first credit bureau in the past decade (Figure 1) and more economies are in the process of establishing one. Banks and other financial institutions can access credit bureau data online in all 117 economies through a website interface or system-to-system connection. Consumers can request access to their credit data online in 77 economies, learn to read and understand their credit report online in 74 economies and dispute their credit data online in 84 economies. In 96 economies, the largest credit bureau provides credit scoring, and 62 of them provide an online explanation of what these scores represent and/or how they are calculated (see Figure 2).
Figure 1. One-third of economies with credit bureaus introduced them in the past decade

Source: Doing Business database.
Figure 2. Where can consumers access, understand and dispute credit information online?
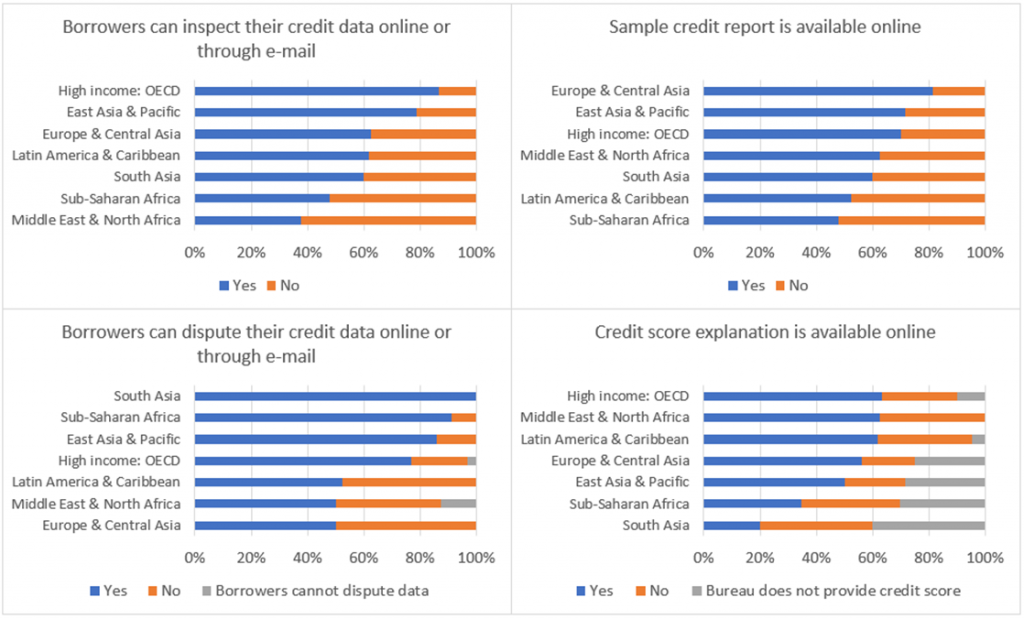
Source: Doing Business database.
In this digital era, new data and technology are shaping the credit reporting sector. Big data and machine learning, for example, allow for faster, more sophisticated, and more cost-effective data mining and processing while lowering the risks associated with human interventions. These technologies hold tremendous potential for credit information sharing.
BIG DATA
Big data refers to what are known as the four Vs: high-volume, high-velocity, high-variety, and high-veracity information assets. Using cost-effective and innovative processing methods, big data allows enhanced insight to support decision-making and process automation. There are two types of data: structured and unstructured. Structured data is information that has been predefined and formatted to a set structure. An example of structured data is a database with precisely defined fields, such as name, address and credit card number. Unstructured data, as the name suggests, comes in all shapes and sizes. Examples include emails, images, audio, video and sensor data. Compared to structured data, unstructured data carries more irregularity and ambiguity, which requires greater data science expertise to store, organize, manipulate and analyze.
Big data can both add value to credit reporting and bring new challenges. Traditionally, credit bureaus focus on specific subsets of structured data, such as loans and repayments, post-paid utilities, demographics and other official data. Transactional data—another type of structured data—includes a large quantity of information that often remains unused. Tobback and Martens (2019) propose a credit scoring model built on fine-grained payment data. Using real-world data of 183 million transactions made by 2.6 million bank customers, the authors show that using payment data allows the detection of twice as many defaulters among the 1% riskiest customers. In the digital era, mobile devices have become a source of massive amounts of structured and unstructured data. Óskarsdóttir et al. (2018) show that combining the big data source of “call networks” with traditional data in credit scoring models significantly increases their performance. In this study, the researchers use call detail records to build call networks and apply social network analytics techniques. This allows them to produce influence scores by simulating influence from prior defaulters throughout the network. Such an assessment, sometimes labeled as “creditworthiness by association,” is controversial, because it can be opaque, discriminatory, and have implications for regulation, data sharing and privacy.
MACHINE LEARNING
Machine learning is a form of artificial intelligence[2] that allows programs to continuously self-improve using existing and new data. Past phenomena can provide valuable information about similar or closely related future phenomena. Machine learning algorithms parse past data, learn from it, and make predictions about future data. Instead of hand-coding specific instructions for a task, programs are “trained” through existing data and algorithms to learn how to perform given tasks. There are many ways that credit information systems could benefit from machine learning.
Leading institutions already use behavioral machine learning to fight against fraud and identity theft. Computers can be trained to discover behavioral patterns across a large volume of streaming transactions. With that knowledge, programs can identify suspicious transactions while adapting to new, previously unseen fraud tactics over time. Machine learning flags potentially fraudulent activities more accurately than traditional rule-based methods. Using the vast repository of fraud data and machine learning models running on high-performance computing infrastructure, PayPal enhanced the accuracy of its automated fraud-detection system by 50 percent.
Machine learning can also improve credit risk modeling. Many factors account for the likelihood of a borrower repaying a loan. Typically, statistical learning methods assume formal relationships between variables in the form of mathematical equations, while machine learning methods can learn from data without requiring any rules-based algorithms. Because of this flexibility, machine learning can better fit patterns in data for calculating credit risks. Bacham and Zhao (2017) analyze the performance of three machine learning methods (random forest, boosting and neural network) in assessing the credit risk of small and medium-sized borrowers, with the RiskCalc model as the benchmark. They find machine learning can better capture non-linear relationships which are common to credit risk. The choice of machine learning algorithm for each job matters. Addo, Guegan and Hassani (2018) use 181 variables and compare the performance of seven machine learning models for predicting the credit risk of enterprises (elastic net, random forest, boosting and four deep learning models). They find tree-based models produce stable results independent of the number of variables used, while deep learning models do not.
With these advantages, it is no surprise that credit bureaus are actively employing machine learning to process big data and produce better insights. For example, Equifax introduced machine learning modeling (neural network) into an explainable artificial intelligence credit score method to generate actionable explanations that are tailored to individual consumers. Equifax is not the only bureau dabbling in machine learning solutions. Experian augmented their analytics tools with machine learning functionalities to generate deeper, on-demand insight. TransUnion and FICO also incorporated machine learning to spot high risk identity behaviors and generate more accurate, understandable scorecards for credit applications. The more recent VantageScore uses machine learning to assess risks and assign scores, even for “credit invisible” consumers without recently updated credit files. Other bureaus such as Creditinfo are working on machine learning model generation platforms.
Overall, modern technologies and advanced solutions allow more efficient processing of a large amount of information. Big data and machine learning can play an instrumental role in expanding access to credit for the unbanked and underserved with thin credit history. Globally, about 1.7 billion adults are still unbanked without an account at a financial institution or through a mobile money provider. Nearly all unbanked adults live in the developing world, and 56 percent of all unbanked adults are women. With big data and machine learning, credit bureaus can develop new ways to assess the creditworthiness for unbanked adults using alternative data. The technologies can help transform massive information into insightful, real-time credit assessment. This helps credit bureaus further reduce information asymmetries, improve risk management, and increase access to credit at lower interest rates. The technologies are opening a new big data world, empowering accelerated financial inclusion.
[1] A credit bureau is defined as a private firm or nonprofit organization that maintains a database on the creditworthiness of borrowers (individuals or firms) in the financial system and facilitates the exchange of credit information among creditors. (Many credit bureaus support banking and overall financial supervision activities in practice, though this is not their primary objective.) While their primary objective is to assist banking supervision, credit registries also collect and share credit information among banks and other regulated financial institutions. This blog focuses on credit bureaus and does not discuss credit registries.
[2] Artificial intelligence (AI) is a complex program that aims at replicating intelligent behavior. Through AI, machines are expected to be able to operate independently with only minor—if any—human interaction.


Join the Conversation