Economists almost never analyze qualitative data. We typically analyze quantitative data from structured survey questions because they are easier to administer to large representative samples of respondents, and easier to analyze using standard econometric methods. However, many questions of interest to economists may be better captured with open-ended qualitative interviews rather than structured questionnaires. These include important concepts like well-being, social norms, cultural change, vulnerability, resilience, decision-making, processes of change in interventions and experiments, and aspirations.
Structured questions work best on concepts where the possible range of responses can be predicted in advance by the researcher and, perhaps more importantly, where respondents have the same understanding of the latent construct underlying the question as the researcher. For concepts where respondents have heterogeneous understandings of the concept and where unpredictable probes and follow ups may be necessary, it may be preferable to allow the respondent freedom to respond in an open-ended conversational style and in the manner of their choosing. Additionally, a trained interviewer can then probe an issue in a relatively unstructured manner by iteratively asking follow-up questions in a more conversational style. This process also has the advantage of eliciting information that is more “reflexive” and "bottom-up”, i.e. driven more by the respondent rather than primarily designed ex-ante by the researcher.
Open-ended approaches to interviews have not been employed much by economists because analyzing them is hard and almost impossible to do at scale with statistically representative samples. They are primarily the domain of qualitative researchers in anthropology, sociology and related fields who mull over recordings or transcripts of interviews for considerable periods of time, listening, reading, interpreting, and carefully coding them within the context of a theory or conceptual framework. Coding remains a labor-intensive process typically done by trained social scientists and is an essential step in conducting nuanced analysis of qualitative data that is based on human interpretation. Interpretative qualitative analysis is consequently associated with small sample studies. Typically, a dataset of, say, 100 interviews is considered a large-N qualitative dataset. This small sample challenge that has been intrinsic to qualitative methods has resulted in a large methodological literature on qualitative and case-study methods focusing on justifying and interpreting data from interviews gathered from samples that are not designed to be statistically representative of larger populations. Their general approach has been to inductively draw out inferences that reflexively expand our understanding of an issue, or to inform theory, rather than claim statistical representativeness.
The advent of Natural Language Processing methods (NLP) tools that treat text-as-data have led some economists to begin to make the case for the analysis of open-ended interviews, which has coincided with growing interest in “narrative economics.” NLP methods broadly fall into two categories: unsupervised methods that extract measures from the text that explain the variation across documents, for example grouping documents into different topics; and supervised methods that extract measures from the text that explain some contextual information about the document. Social science applications of NLP to open ended interviews have generally focused on unsupervised methods. These methods essentially reduce the dimensionality of the text to make it more analyzable. Researchers then interpret the data by analyzing these computer-generated representations of text. A potential drawback here is that rather than basing interpretation on a reading of the documents, researchers interpret the simplified representations of the text. Furthermore, as unsupervised models are typically “unguided”, i.e., they do not seek to extract a particular signal from text, it can often be that the resulting measures are not suited to the research question of interest. Therefore, unsupervised NLP methods generally do not permit the kind of interpretative qualitative analysis done by anthropologists and sociologists where humans rather than machines code and classify the data.
In a recent paper we develop a “supervised” NLP method that allows open-ended interviews, and other forms of text, to be analyzed using interpretative human coding. As supervised methods require documents to be “labelled”, we use interpretative human coding to generate these labels, thus following the logic of traditional qualitative analysis as closely as possible. Briefly, a sub-sample of the transcripts of open-ended interviews are coded by a small team of trained coders who read the transcripts, decide on a “coding-tree,” and then code the transcripts using qualitative analysis software which is designed for this purpose. This human coded sub-sample is then used as a training set to predict the codes on the full, statistically representative sample. The annotated data on the “enhanced” sample is then analyzed using standard statistical analysis, correcting for the additional noise introduced by the predictions. Our method allows social scientists to analyze representative samples of open-ended qualitative interviews, and to do so by inductively creating a coding structure that emerges from a close, human reading of a sub-sample of interviews that are then used to predict codes on the larger sample. We see this as an organic extension of traditional, interpretative, human-coded qualitative analysis, but done at scale.
This method has interpretative advantages over “unsupervised” NLP methods, but it also has an advantage over methods which map text against pre-defined dictionaries of, for example, positive and negative words. While these dictionaries are very well developed in some areas, such as sentiment analysis for economic and financial news, in many cases a relevant dictionary may not be available for a particular research question, language or cultural context. Furthermore, before an in-depth reading of the documents it might not be clear what sort of dictionary might be relevant. Working with human codes in a sub-set of the data falls in the category of “supervised” NLP methods – but gives us a training set that is specific to the sample being analyzed, and thus has the potential for nuanced, context-specific analysis. It is thus analogous to a dictionary created specifically for the analytic sample. Furthermore, we do not need to guess at the interpretation of our text-based measures, as they are a product of our interpretative coding process. We believe the method has wide applicability for a variety of questions.
In our paper we apply this method to study parents’ aspirations for their children by analyzing data from open-ended interviews conducted on a sample of approximately 2,200 Rohingya refuges and their Bangladeshi hosts in Cox’s Bazaar, Bangladesh. Aspirations are an interesting subject to apply this method, because an open-ended approach allows us to study dimensions of aspirations that are difficult to capture in structured questionnaires. The literature on aspirations in development economics focuses on what the philosopher Agnes Callard has called “ambition” - specific goals that parents may have for their children such as a level of education, or a profession. Open-ended interviews allow us to expand this to explore its moral and spiritual dimensions - what Callard calls “aspiration” to distinguish it from “ambition” - such as being a “good person” or being religiously inclined. They also allow us to study what the anthropologist Arjun Appadurai has called the “capacity to aspire” or the capacity to navigate your way to achieving a given goal.
The respondents all participated in an extensive household survey in 2019 covering questions related to demographics, assets, living standards, migration history and trauma. In two subsequent survey rounds in 2020 and 2021 an adult member of the household was asked the following open-ended questions on aspirations (along with other topics):
1) Can you tell me about the hopes and dreams you have for your children?
2) What have you done to help them achieve these goals?
Their responses to these questions - with some conversational interaction and probing by the interviewers – averaged for about 10 minutes. The interviews were recorded, transcribed, and translated into English. We randomly selected 300 transcripts in the first round, and 400 in the next round, stratified by refugee status and gender, to be carefully read and coded by researchers led by a highly qualified qualitative sociologist. Based on a close reading of a subset of our interviews, we develop a coding tree that categorized aspirations, ambitions, and navigational capacity along a range of dimensions, as shown in Figure 1.
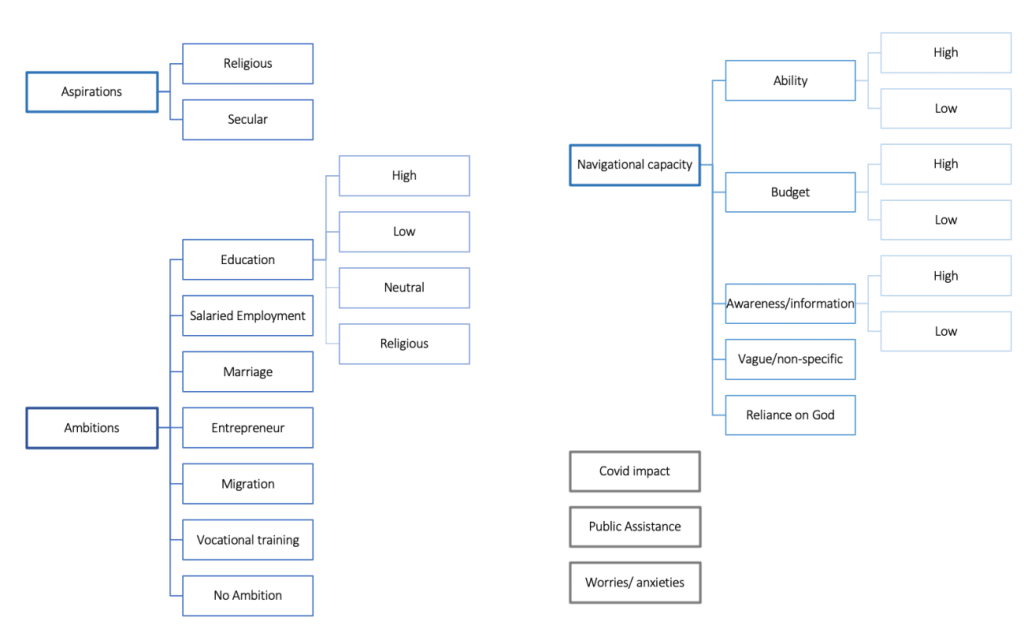
We apply the method we develop to scale up this interpretative qualitative coding to our full sample of 2,200 interviews. This allows us to differentiate between, and analyze the correlates of, ambition, navigational capacity, and aspirations among Rohingya refugees and their Bangladeshi hosts. We demonstrate in the paper that they are independent concepts that have distinctly different determinants which suggest different policy responses. For example, we find that while refugees generally have lower ambitions for their children, they generally display a higher capacity to achieve those ambitions. We also find that subjects are more likely to express secular aspirations for male children than for their female children. Table 1 below shows the estimated coefficients on indicators for refugee status and female eldest child in regressions for secular aspirations and low ability. With the smaller sample size of the human annotated interviews (the first and third columns) these coefficients are not significant at 5%, but with the larger enhanced sample (the second and fourth columns) the coefficients are highly significant. This illustrates the key advantage of our method – we are able to use the nuanced and detailed codes that emerge from interpretative qualitative analysis, but at a sample size that allows for statistical inference.
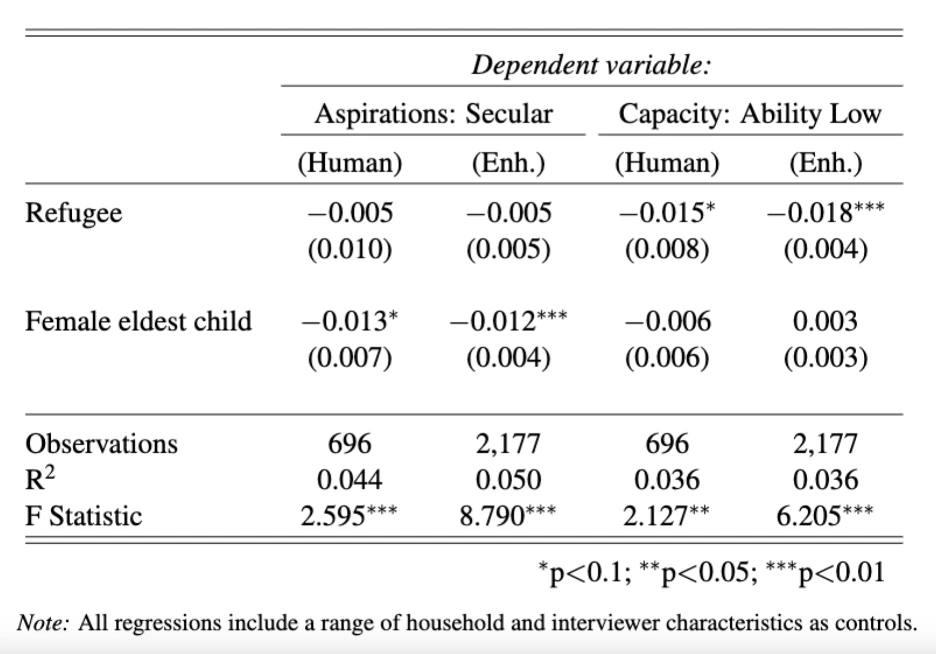
The application to aspirations illustrates some of the advantages of our combination of interpretative human coding with supervised NLP methods. Our metrics can capture nuance that traditional quantitative survey questions might miss. Some concepts, like navigational capacity, would be inherently difficult to measure with a structured survey question. Other variables like educational ambition are easier to quantify, but we show that our qualitative variables add important color and context to more quantitative measures of ambition.
Unsupervised NLP analysis provides too coarse of a decomposition of the text, which may not be suited to many research questions, as we show by comparing our results to those using a Structural Topic Model. This topic model shows that there are clearly differences in the language used by, for instance, hosts and refugees. However, interpreting these differences in terms of aspirations, ambition and navigational capacity is difficult. Unsupervised methods can thus uncover interesting dimensions of variation in text data, but they will often not give interpretable answers to specific research questions.
An alternative to our combination of interpretative human coding and NLP would be to simply code the entire sample manually. However, this is not only expensive and impractical, it also loses the advantage of being annotated by a small highly-quality team of trained social scientists who can discuss and agree on an interpretation.
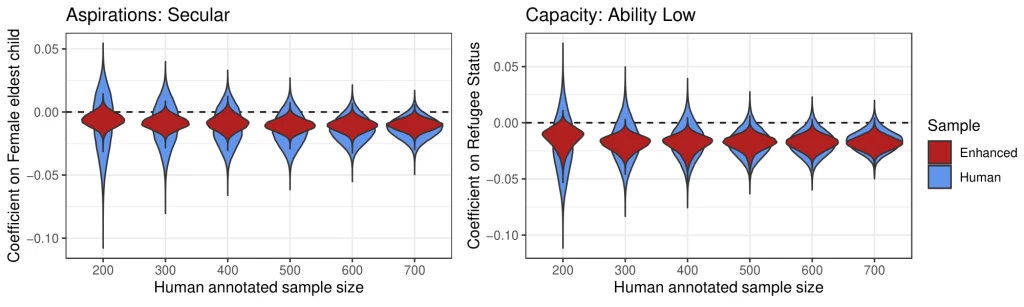
In a series of simulations, illustrated in Figure 2, we show that for most researchers enhancing their human coded sample with machine annotation is likely to be optimal. Figure 2 shows the evolution of two of the regression coefficients reported in Table 1 as we increase the number of human-annotated interviews. In the left hand panel we show the distribution of the coefficient on female child in a regression for secular aspirations, and in the right hand panel the distribution of the coefficient on refugee status in a regression for low ability. As we move from the left to the right the number of human annotated interviews increases from 200 to 700. The distribution of the estimated coefficients on the human annotated sample is shown in blue, with the enhanced sample coefficient distribution shown in red. As the size of the human annotated sample increases the distribution of the estimated coefficients get tighter as the estimate gets more precise. In all cases the coefficients are more precise in the enhanced sample than in human annotated sample, thanks to the larger sample size. Crucially, we can see that the benefits of enhancing the sample are seen even when a relatively small number of interviews are human annotated. Given the expense associated with expert human annotation, we therefore find that for most (budget constrained) researchers machine annotating part of their sample is likely to be optimal.
In future work, we intend to apply our methodology to a range of further questions including wellbeing and discrimination, both in Cox’s Bazaar and elsewhere. We are also exploring the potential benefits of applying pre-trained large language models, such as the well-known ChatGPT, in combination with qualitative analysis.


Join the Conversation