Can another researcher reuse the same code on the same data and get the same results as a recently published paper? This may sound like a low bar for reproducibility: this is presumably how the paper was written in the first place! Yet, at the AER, only 2 out of 5 accepted papers pass this “computational reproducibility” check on the first pass. Clearly, we all have a lot of work to do to live up to reasonable reproducibility standards — and the new AEA data policy guidelines underscore the scope of this effort. This question motivated teams from the World Bank, 3ie, BITSS/CEGA, J-PAL, and Innovations for Poverty Action (IPA) to host researchers from the US Census Bureau, the Odum Institute, Dataverse, the AEA, and several universities at the first Transparency, Reproducibility, and Credibility research symposium last Tuesday.
So, what happened?
Each of the host organizations introduced the work that they are doing to support high-quality research by the teams they work with, and Ted Miguel spoke in detail about the challenges and opportunities of the present moment in research transparency. All talks can be found here. Afterwards, research practitioners discussed their experiences in panels focused on three key topics: defining transparency in research; balancing privacy and openness in data handling; and practical steps forward on credible research. Here we share some of the highlights of the discussions.
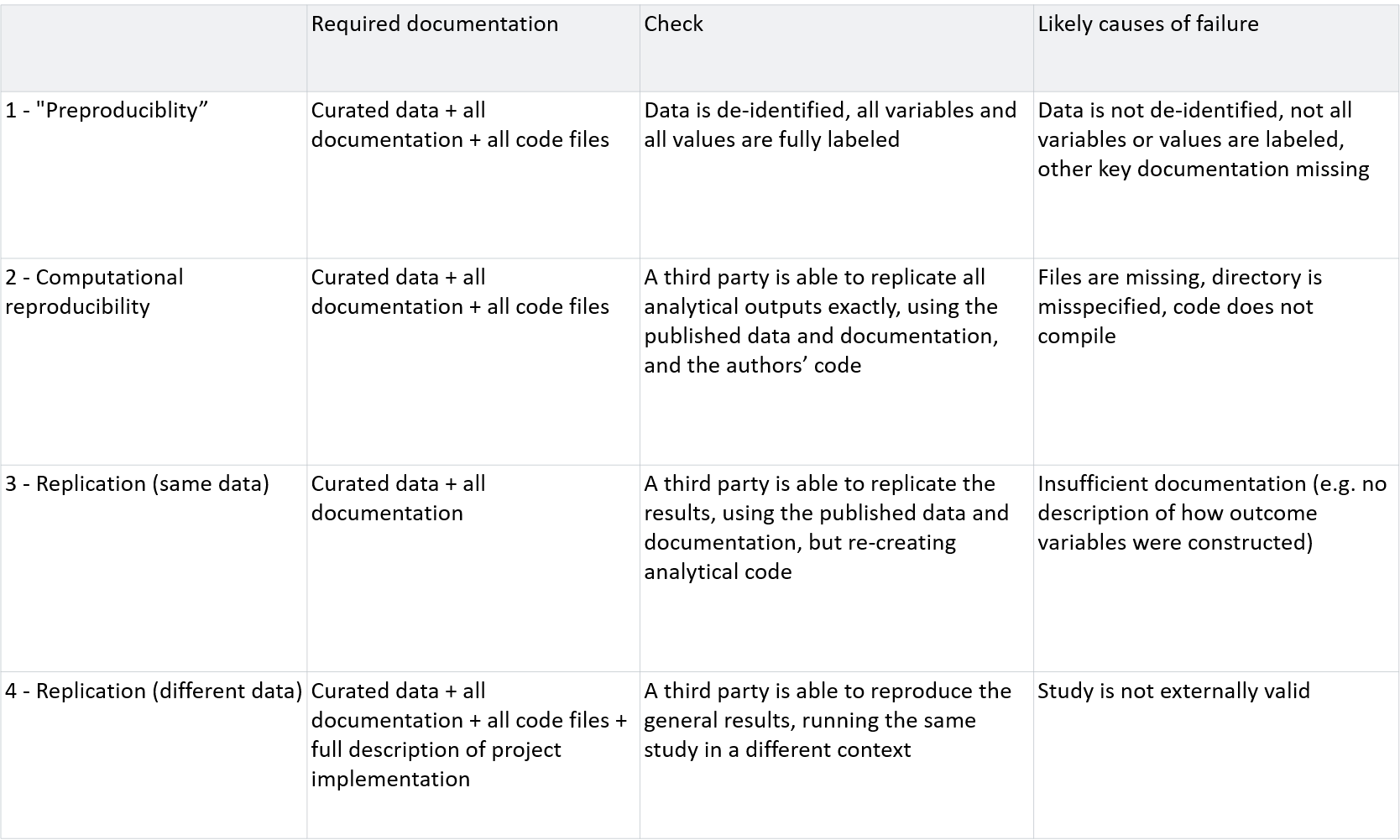
First up: defining the terms. “Reproducibility” and “replicability” are often confused (case in point: a ‘push-button replication’ is in fact a check for computational reproducibility). Prof. Lorena Barba, one of the authors of a 2019 report by the National Academies of Science, Engineering and Medicine, offered the following definitions. Reproducibility means ‘computational’ reproducibility: can you obtain consistent computational results using the exact same input data, computational steps, methods, code, and conditions of analysis? Replicability means obtaining consistent results across separate studies aimed at answering the same scientific question, each of which has obtained its own data.
Reproducibility and transparency are not binary concepts: there’s a spectrum, starting with simple materials release. But even getting that first stage right is a challenge. An analysis of 203 empirical papers published in top economics journals in 2016 showed that less than 1 in 7 provided all the data and code needed to assess computational reproducibility (Gertler et al 2017). A scan of the 90,000 datasets on the Harvard Dataverse found that only 10% have the necessary files and documentation for computational reproducibility (and a check of 3,000 of those that met requirements found that 85% did not replicate). Computational reproducibility checks should be quick: 3ie, which now does computational reproducibility checks for all its publications, reported an average of 3 hours spent per paper. Making computational reproducibility checks a norm at all research institutions would be an easy win for research transparency.
Privacy concerns
Complete data publication, unlike reproducibility checks, brings along with it a set of serious privacy concerns, particularly when sensitive data is used in key analyses. The group discussed a number of tools developed to help researchers de-identify data (PII_detection from IPA, PII_scan from JPAL, and sdcMicro from the World Bank). But is it ever possible to fully protect privacy in an era of big data? One option is to add noise to data, as the US Census has proposed, as it makes the trade-off between data accuracy and privacy explicit. But there are no established norms for such “differential privacy” approaches: most approaches fundamentally rely on judging “how harmful” disclosure would be. And even that approach does not work in all cases, for example, impact evaluations designs that rely on geo-identifiers and, for instance, proximity to a well-known infrastructure, such as spatial discontinuity designs. At the very least, we need additional institutional investments to create permanent, secure, and interoperable infrastructure to facilitate restricted and limited access to sensitive data.
How do we get there?
Finally, the group discussed practical steps to advance the agenda of reproducibility, transparency, and credibility in research. Ideas included incorporating transparent practices into academic training at all levels and verifying computational reproducibility of all research outputs within each institution. Pre-publication review, for example, is a practice DIME has instituted department-wide: over the past two years, no working paper has gone out without computational reproducibility being confirmed by the Analytics team. This was not a quick win: 18% of submissions did not replicate on the first run (e.g., set your seeds!), and two-thirds of these had to be resubmitted more than once.
Longer-term goals to meet reproducibility and transparency standards include making tools for research transparency part and parcel of the quest for efficiency gains in the research production function. People seem to systematically underestimate the benefits and overestimate the costs to adopting modern research practices. But the group also recognized that adoption of these practices is hard: the costs are front-loaded, few onboarding resources exist for many teams to rely on, and the benefits of these process improvements often lie far in the future. Demonstration and peer effects may be large.

How does the rest of research community feel about this?
In a particularly relevant presentation, Guadalupe Bedoya from DIME presented data from a recent short survey designed to survey practitioners’ application of classic “best practices” that are fundamental to reproducible research. The team surveyed principal investigators in top development economics organizations based on the IDEAS ranking and received responses from 99 PIs, as well as from 25 DIME research assistants. (Their complete material can be found here.) The main results are presented in the panel figure below. On a scale from 1 to 5, PIs that responded rate their preparedness to comply with the AEA’s new policy at 3.5. On specific practices related to concepts that are well-known to facilitate reproducibility and reduce the probability of errors (and may also increase productivity), there were some fascinating results:
-
- 80% of respondents use dates and/or initials to control version of files
- 80% use e-mail to manage tasks for data analysis and coding
- only 33% use a fixed folder structure
In other words, practitioners’ perception of their readiness to meet reasonable reproducibility standards did not necessarily match their actual readiness. One issue cited by researchers is the high entry cost to changing their workflow to absorb new practices. Many respondents worried that enforcing reproducibility standards would only accentuate the inequality between researchers. The fear articulated by some respondents was that well-established researchers, have more access to funds, training and staff(e.g. more research assistants)--all of which lower the entry costs. But this is not necessarily true for the average empirical researcher. Researchers who work by themselves or in smaller teams felt it would be hard for them to catch up. They would have to either give up precious research time to learn new protocols, or would have to invest more time in raising extra funds to hire or train more research assistants.
The good news is, there are lots of ongoing efforts and increasing availability of resources to help researcher meet the bar with reasonable cost and effort! The incentives are starting to align, as shown by the AEA’s new data policy as well as funding requirements from donors such as 3ie. Research organizations are stepping up even more to help researchers adopt reproducible practices. For example, to help researchers comply with the mandatory pre-publication review of working papers mentioned above, DIME has developed an extensive technical training curriculum. There was broad agreement from the group that increased investment in curriculum and tools development and technical training and collaboration — lowering entry costs — would improve both the efficiency as well as the transparency of many research teams.





Join the Conversation