
Developing countries face a data conundrum. Despite more data being available than ever in the world, low- and middle-income countries often lack adequate access to valuable data and struggle to fully use the data they have.
This seemingly paradoxical situation represents a data divide. The terms “digital divide” and “data divide” are often used interchangeably but differ. The digital divide is the gap between those with access to digital technologies and those without access. On the other hand, the data divide is the gap between those who have access to high-quality data and those who do not. The data divide can negatively skew development across countries and therefore is a serious issue that needs to be addressed.
Extent and Challenges of the Data Divide
Huawei has estimated that by the 2030s, humanity is expected to generate one yottabyte of data (that’s 10 to the power of 24 bytes) every year. However, with almost half of the global population still offline, equal access to data and realizing opportunities to reap the benefits of data-driven development will remain out of reach, particularly in the world’s poorest countries, where nearly two thirds of people lack access to the internet.
Multiple challenges prevent data from being generated, stored, used, and reused to its full potential. These challenges include the lack of access to infrastructure, untapped data sets, and a lack of awareness and data-related skills. Further, insufficient financing, low technical capacity, weak institutional arrangements, and policy gaps compound the problem.
First, there is often a lack of system-wide vision or strategy for data, and governments operate in fragmented silos. As the 2021 World Development Report: Data for Better Lives advises, these shortcomings can be addressed through “integrated national data systems.” Such systems include data standardization, which refers to establishing common formats, definitions, and structures for data and ensuring interoperability, or the ability of different systems and organizations to work together and exchange data. By breaking down barriers to data sharing, interoperability can enable more stakeholders to access and use data, regardless of technological capabilities or resources. These are key priorities supported by the new, Bank-hosted Global Data Facility trust fund.
Second, as also pointed out by the 2021 World Development Report, is the need to enable equitable access to data, particularly for poor and marginalized people. It is essential to help them benefit from the social and economic value of data, besides protecting them from data misuse. Strong data governance can help foster equity, value, and trust by establishing safeguards that protect the rights of data producers, users, and enablers, and facilitate the responsible use and reuse of data.
Third, cybersecurity is a key cross-cutting issue. Security-by-design and privacy-by-design are essential components to maximize the value of data and ensure that people can access, correct, and monitor how their data are used. Such design approaches can ensure that marginalized and disadvantaged groups have agency over their data without fear of discrimination and exclusion. The Bank’s Cybersecurity Multi-Donor Trust Fund operationalizes these and related priorities.
Effects of the Data Divide
The effects of the data divide are alarming, with low- and middle-income countries getting left behind. McKinsey estimates that 75% of the value that could be created through Generative AI (such as ChatGPT) would be in four areas of economic activity: customer operations, marketing and sales, software engineering, and research and development. They further estimate that Generative AI could add between $2.6 trillion and $4.4 trillion in value in these four areas.
PWC estimates that approximately 70% of all economic value generated by AI will likely accrue to just two countries: the USA and China. These two countries account for nearly two-thirds of the world’s hyperscale data centers, high rates of 5G adoption, the highest number of AI researchers, and the most funding for AI startups. This situation creates serious concerns for growing global disparities in accessing benefits from data collection and processing, and the related generation of insights and opportunities. These disparities will only increase over time without deliberate efforts to counteract this imbalance.
Technological advancements can also exacerbate this imbalance. Generative AI is a topical example of how we might see a widening data divide, even as technology will likely have many positive impacts. For now, developing foundational models for Generative AI is expensive, and only the biggest tech companies can afford their development. Further, Generative AI models are trained on large datasets, which often result in biases due to inequality in the volume and availability of training data, for example, from developed versus developing countries. Moreover, the distribution of cloud infrastructure is presently heavily skewed in favor of developed countries (see Figure 1).
Figure 1. Data Center Map. Number of data centers
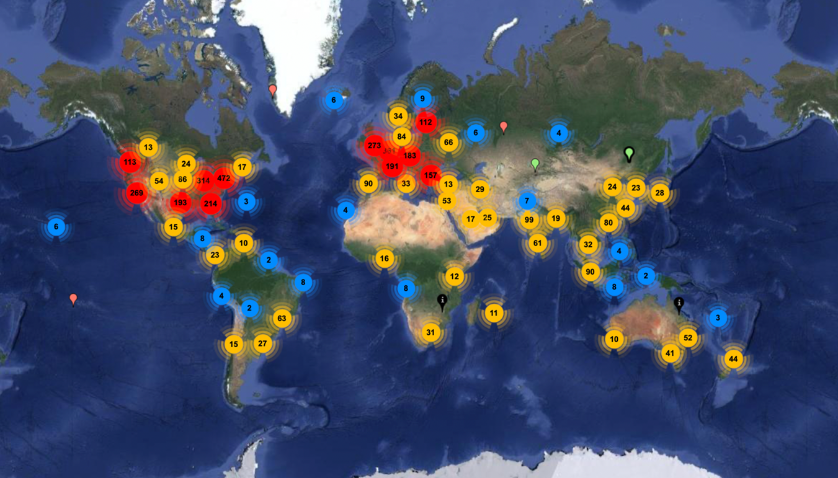
Source: https://www.datacentermap.com/
Possible Solutions and How the World Bank Can Help
Addressing the data divide will require a broad range of actions. These include regulations on data protection, standards, cybersecurity, artificial intelligence, open data, cross-border data flows, data markets, exchanges, and data spaces. According to Gartner, 60% of AI will be based on synthetic data by 2024. Hence initiatives on synthetic data will be necessary to augment data availability, especially for training AI. Investments in digital infrastructure, e.g., data centers, cloud computing, blockchain infrastructure, and broadband connectivity, will be required. Further, data literacy and the skills and competencies to design, develop, deploy, manage, and maintain data-centric services and solutions will be necessary. Similarly, digital economy partnership agreements must be instituted to facilitate cross-border data flows and improve data access.
Recognizing the importance of tackling these elements, the World Bank is increasingly prioritizing technical support and more financing to help establish integrated national data systems and strengthen country data systems, data capital, and data infrastructure to maximize the benefits of data for all stakeholders and to enshrine data as a public good.



Join the Conversation