 Around 40 percent of households in Indonesia receive regular social assistance programs. Photo: © Ray Witlin / World Bank
Around 40 percent of households in Indonesia receive regular social assistance programs. Photo: © Ray Witlin / World Bank
Electronic devices enable innovations in survey design, such as questionnaires that adapt to responses. Our recently published working paper describes the method and results in more detail, leveraging the potential to create a new survey-based tool for determining household eligibility for social assistance benefits. Around 40 percent of households in Indonesia receive regular social assistance programs. Besides categorical criteria, such as households with children, programs use another targeting method to determine eligibility called proxy means testing (PMT which collects a set of household characteristics during a home visit, and then using a statistical model estimates consumption level as a measure of economic wellbeing. Generally, the households whose estimated consumption falls below the eligibility threshold receive assistance.
The cost of PMT data collection is significant because some social registries contain data on over half a country’s population. Only a census compares to such a large data collection exercise. But although a census covers more households, it collects less information. In locations where targeting surveys are conducted as a ‘sweep’, thousands of enumerators need to be paid for their time and travel costs. As a result, survey “sweeps” are only conducted every few years. This is not ideal because poverty is dynamic, and the true eligibility status of many households, changes. Importantly, although the survey cost is usually moderate in relation to the benefits, the high absolute survey cost may also limit the number of households surveyed. This in turn leads to many missing out on benefits because they were never captured in the survey. With a given budget, lower survey costs per household would either allow more frequent surveys—for a more dynamic assessment—or a broader coverage that reaches more intended beneficiaries.
Based on two basic ideas, we have developed a method that follows the PMT approach but has the potential to reduce survey costs substantially. First, many of the questions in a typical targeting questionnaire are highly correlated; knowing one answer means that we may not need to know others. For example, if we already know what type of material the home’s roof is made of, asking what type of wall material the home has doesn’t offer additional insight on the family’s financial situation. Selecting a small set of highly predictive variables reduces redundancy without losing predictive power. Ordering questions from most to least predictive, figure 1 below shows the number of questions that are needed to reach a certain level of exclusion error rate (EER), for example, the share of eligible households falsely deemed ineligible. Each line shows the performance of one variable selection method on data from Indonesia’s SUSENAS survey (a gradient boosting machine, or GBM, is the underlying predictive model, except in the group lasso case). For forward stepwise selection, the result indicates that a full questionnaire of 37 questions only gains a 0.3 percentage point EER reduction from its final 22 questions. Policymakers can use the simulated results to decide the level of accuracy penalty they are willing to accept for shorter questionnaires.
Figure 1: Questions needed to achieve a targeting accuracy level with Truncated Questionnaires

The second idea is that knowing if a household is well-off and thus ineligible, or vice versa, should become quickly obvious. In an approach we call early stopping, we ask the most salient questions first, and deploy quantile regression after each question to create a prediction interval that indicates plausible consumption values based on the answers collected so far. The interview ends when the PMT’s eligibility threshold falls outside the range of plausible values, at which point the current predicted value is logged as the consumption estimate. Figure 2 illustrates a sample household that requires 12 questions to become certain enough that its consumption level is low enough to establish eligibility.
Figure 2: Household example of Early Stopping, logging estimated consumption after 12 questions

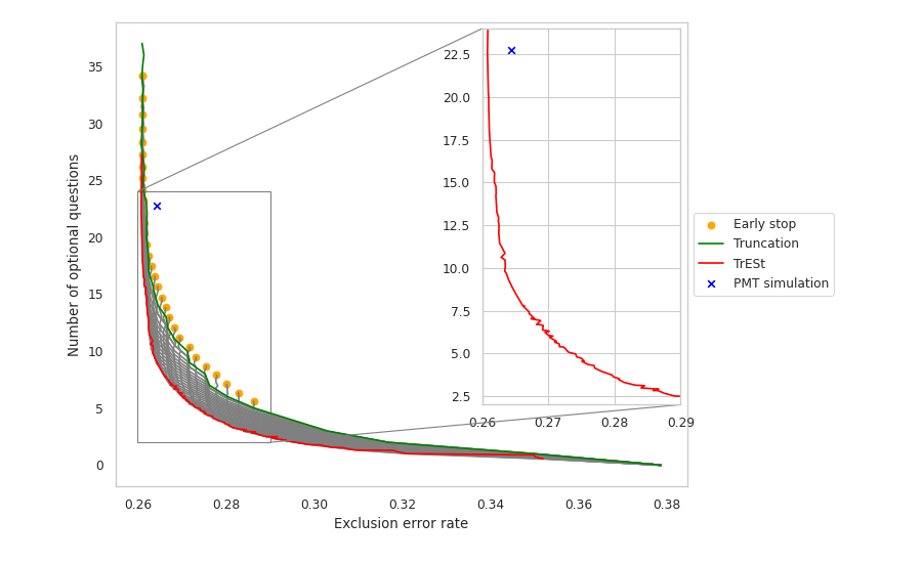
To recap, the first approach orders the questions by their predictive power and truncates the questionnaire at a length that yields the desired accuracy for the average household. The second approach asks questions in the same sequence, without truncation, and stops enumeration early when there is enough evidence to decide if a household is either clearly eligible or ineligible. Since these approaches rely on different mechanisms, they can also be combined for an approach we call Truncated Early Stopping, or TrESt. Figure 3 shows that this method can achieve a given level of accuracy with fewer questions than each component approach on its own. The vertical difference between the yellow dots (early stopping) or green line (truncated questionnaire) and red line (TrESt) shows a substantial improvement: roughly 10 versus 15 questions at an exclusion error rate around 26.4 percent. The zoom portion compares TrESt with a standard PMT baseline similar to the one currently used in Indonesia. Where the basic PMT selects roughly 23 questions, TrESt only needs around 10 questions to match its accuracy level.
Figure 3: Truncated Early Stopping outperforms its component methods
Our new working paper presents information that is valuable for providing policymakers a choice on cost versus accuracy to fit their context and constraints. The discussion section highlights important caveats. For example, feasible savings depend on both geography – the longer the travel time, the smaller the relative gain from shorter questionnaires – and the variety of programmes and associated thresholds that the questionnaire must cater to . Finally, the working paper includes a simulation of applying TrESt in Jakarta, where the time saved through shorter questionnaires could be used to survey more households, and thus reduce overall exclusion errors.




Join the Conversation