Para algunos, la inteligencia artificial es un término misterioso que hace pensar en robots y supercomputadoras. Pero la verdad es que los algoritmos de aprendizaje automático y sus aplicaciones, si bien son potencialmente complejos desde el punto de vista matemático, son bastante fáciles de entender. De hecho, los expertos en gestión de riesgos de desastres y resiliencia usan cada vez más algoritmos de aprendizaje automático para recopilar mejores datos sobre el riesgo y la vulnerabilidad, tomar decisiones más informadas y, en última instancia, salvar vidas.
La inteligencia artificial y el aprendizaje automático se usan como sinónimos, pero la primera tiene implicaciones más amplias que el segundo. La inteligencia artificial (general) evoca imágenes de futuros distópicos del tipo “Terminator”, aunque en realidad, lo que tenemos ahora y lo que tendremos durante mucho tiempo son simples computadoras que aprenden a partir de los datos de manera autónoma o semiautónoma, en un proceso conocido como aprendizaje automático.
La nota de orientación sobre el uso del aprendizaje automático en la gestión de riesgos de desastres (i) preparada por el Fondo Mundial para la Reducción de los Desastres y la Recuperación (GFDRR) (i) aclara y desmitifica la confusión en torno a los conceptos de aprendizaje automático e inteligencia artificial. Se ilustran y destacan algunos estudios de casos específicos que muestran las aplicaciones de aprendizaje automático en este ámbito. El documento es útil para diversas partes interesadas, incluidos profesionales del área, especialistas en datos sobre riesgos, o toda persona que tenga interés en la informática.
Aprendizaje automático sobre el terreno
En un estudio de caso, imágenes de drones y a nivel de la calle se enviaron a algoritmos de aprendizaje automático para detectar automáticamente edificios con “piso débil” o aquellos con mayor probabilidad de colapsar en un terremoto. El proyecto fue desarrollado por el Equipo de Apoyo y Operaciones Geoespaciales (GOST) del Banco Mundial en la Ciudad de Guatemala, y es solo una de las muchas aplicaciones donde grandes cantidades de datos, procesados mediante aprendizaje automático, pueden tener impactos muy tangibles y significativos en salvar vidas y propiedades durante un desastre.
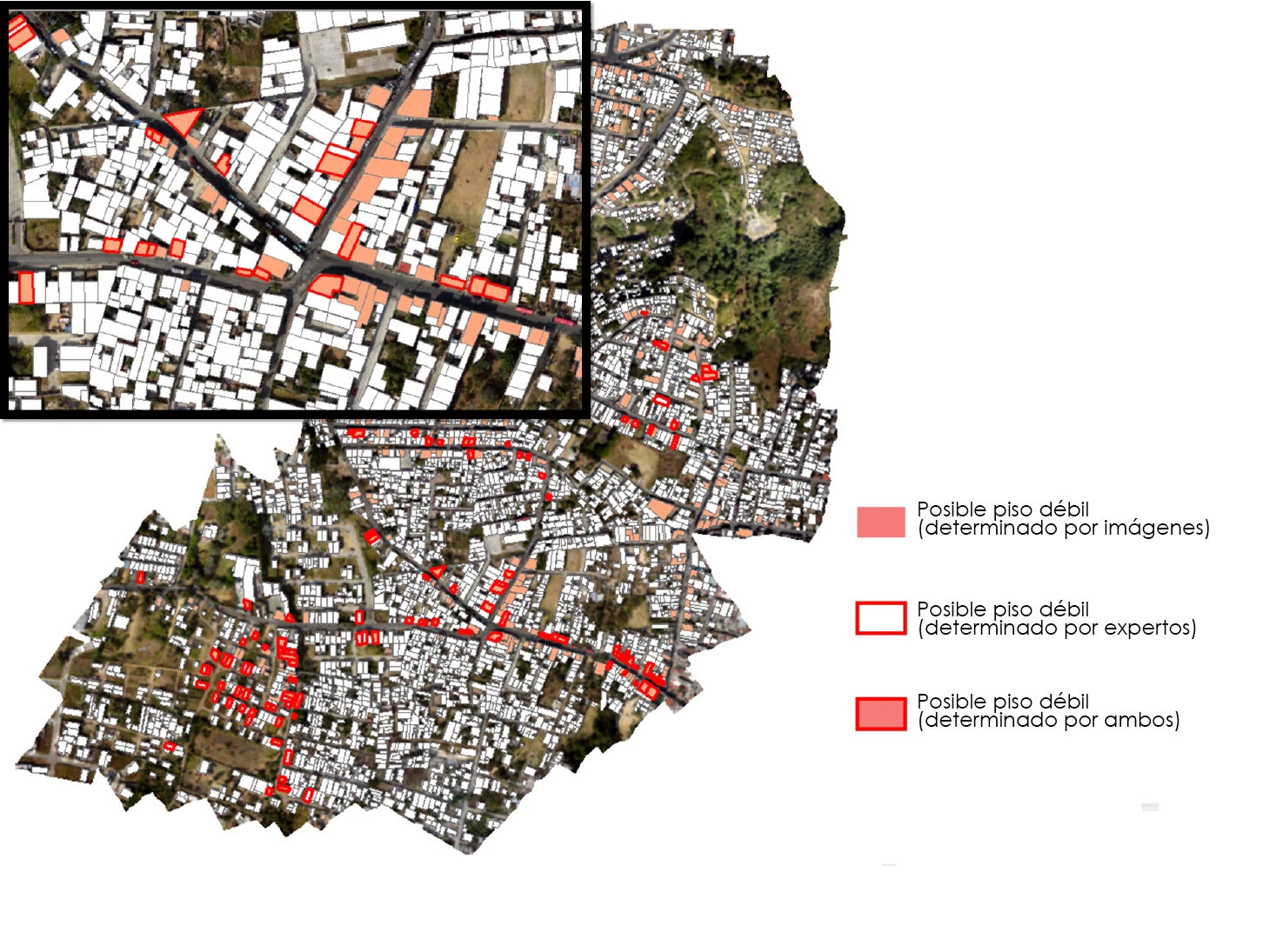
En otro caso, el aprendizaje automático se usó para procesar imágenes satelitales con el fin de separar asentamientos informales, a veces denominados barrios de tugurios, de los asentamientos formales y planificados. El proyecto dirigido por Jordan Graesser y el Laboratorio Nacional de Oak Ridge (i) se realizó en colaboración con el Banco Mundial, y GOST está implementando los métodos para aplicarlos a otros casos.

El impacto de este tipo de trabajo no puede ser subestimado, ya que poner los vecindarios y las personas más vulnerables en el mapa nos permite definir con mayor exactitud la vulnerabilidad de las poblaciones a los peligros. Un mapeo de la vulnerabilidad más preciso es uno de los cimientos de una gestión más eficaz de los riesgos de desastres. Otras metodologías han tenido éxito recopilando información exacta sobre vulnerabilidades, por ejemplo, agregando más “botas en el terreno” para aplicar técnicas de prospección o duplicando las campañas de colaboración masiva en un esfuerzo por trazar mapas comunitarios. Usar algoritmos de aprendizaje automático puede reducir enormemente los costos de un proyecto, ya sea que se aplique a imágenes satelitales, de drones o a nivel de la calle, o datos de sensores y de fuentes completamente diferentes, como sensores sísmicos o publicaciones en redes sociales.
Democratizar los datos, minimizar los sesgos
La Iniciativa de Datos de Libre Acceso sobre Resiliencia (OpenDRI) (i) del GFDRR promueve el uso integrado de estas tecnologías para maximizar el impacto de los proyectos y minimizar los costos. La creación de mapas automatizada a partir del aprendizaje automático, las campañas de colaboración masiva para recopilar datos de “capacitación” y “validación” y el análisis de estos datos por parte de expertos pueden y deben vincularse entre sí sin problemas. Los datos de prueba y de capacitación se usan para “enseñar” (capacitar) a los algoritmos de aprendizaje automático y luego evaluar (probar) qué tan bien funcionan. Los conocimientos especializados son necesarios para recopilar datos “fidedignos sobre el terreno”, implementar software de aprendizaje automático y analizar resultados de forma efectiva.
Los datos de libre acceso significan que los ingresos y las salidas de datos de los proyectos deben estar disponibles libremente y ser fáciles de usar. Al estar abierto a todas las partes interesadas, el proceso de gestión de riesgos de desastres se democratiza. La propiedad de los datos depende entonces de las comunidades a las que se refieren, llevando a estas a tener sus propios proyectos de gestión de riesgos de desastres y, por consiguiente, tener las recomendaciones resultantes. El desarrollo de capacidad y la colaboración masiva son un componente vital de los proyectos que se centran en integrar datos abiertos, ya que por definición estas actividades involucran a las comunidades en la creación y el intercambio de datos.
Minimizar el sesgo en todos los proyectos es de suma importancia. El solo hecho de que las computadoras estén analizando y procesando datos usando el aprendizaje automático, no significa que todo el proceso sea aséptico y esté libre de sesgos. Notoriamente, los modelos de computadora solo son tan buenos como sus datos de entrada. Por lo tanto, los sesgos en los datos de entrada pueden persistir en los resultados. Los sesgos pueden afectar las estrategias de mitigación que protegen a las personas y las comunidades y, por lo tanto, tienen un gran impacto en la pérdida de vidas y propiedad.
Más que unas palabras de moda
La inteligencia artificial y el aprendizaje automático se han convertido en palabras de moda en los últimos años, reemplazando de algún modo los términos “macrodatos” y “ciencia de datos”. En realidad, todos estos términos se refieren al mismo conjunto de métodos informáticos basados en estadísticas que se usan para analizar datos, separar datos y actuar en función de ellos. Los métodos de aprendizaje automático simplemente hacen esto en programas recursivos o algoritmos que aprenden de los datos ingresados para mejorar los resultados posteriores.
Los algoritmos de aprendizaje automático ya alimentan a internet en las tiendas en línea, los motores de búsqueda, los anuncios dirigidos a ciertas audiencias y las redes sociales. También alimentan nuestros hogares gracias a la creciente aparición de dispositivos de asistente de voz y casas inteligentes, y el mundo móvil con asistentes personales, comandos de voz y traducción instantánea, solo por nombrar algunas aplicaciones. ¿Cómo sería el mundo si aprovecháramos todo ese poder de la computación automatizada para proteger a las personas?
MÁS INFORMACIÓN
- Recursos de la Iniciativa de Datos de Libre Acceso sobre Resiliencia (OpenDRI) del GFDRR (i)
- Publicación: Aprendizaje automático para la gestión de riesgos de desastres (i)
- Blog: Tres enfoques innovadores para la gestión de riesgos de desastres (i)
- Video: Ahmad Wani en UR2018: ¿De qué manera la inteligencia artificial puede ayudar a promover la inclusión social? (i)


Únase a la conversación