L’« intelligence artificielle » peut apparaître à certains comme un terme mystérieux évoquant essentiellement des robots et des supercalculateurs. Pourtant les algorithmes d’apprentissage automatique et leurs applications, même s’ils peuvent être complexes sur le plan mathématique, sont relativement simples à comprendre. D'ailleurs, les spécialistes de la gestion des risques de catastrophe et de la résilience les utilisent de plus en plus pour collecter des données plus fiables sur les risques et la vulnérabilité, prendre des décisions mieux éclairées et, en définitive, sauver des vies.
Bien que l’on utilise souvent indifféremment les deux termes, les implications de l’intelligence artificielle vont bien plus loin que celles de l’apprentissage automatique. L’intelligence artificielle évoque des images de futurs sombres, comme dans Terminator, mais en réalité, ce dont nous disposons aujourd'hui et pour longtemps encore, ce sont simplement d’ordinateurs qui apprennent à partir de données, de manière autonome ou semi-autonome — d’où le terme d’apprentissage automatique ou machine learning en anglais.
Une note d'orientation (a) publiée par la Facilité mondiale pour la prévention des risques de catastrophe et le relèvement (GFDRR) (a) clarifie et démystifie les concepts d'apprentissage automatique et d'intelligence artificielle. Plusieurs études de cas spécifiques illustrant les applications de l’apprentissage automatique pour la gestion des risques de catastrophe y sont détaillées. Cette note d’orientation est précieuse pour de nombreux acteurs, qu’il s’agisse des professionnels de la gestion des risques de catastrophe sur le terrain, des spécialistes des données sur les risques ou de toute autre personne intéressée par ce domaine de l’informatique.
L'apprentissage automatique sur le terrain
Dans l’une de ces études de cas, des images prises par des drones et des photos à l’échelle de la rue ont été intégrées aux algorithmes pour détecter automatiquement les bâtiments dont la structure est fragile ou les plus susceptibles de s’effondrer lors d’un séisme. Il s’agit d’un projet mis en œuvre à Guatemala City par l’équipe d’appui aux activités de géolocalisation de la Banque mondiale (GOST), et c’est l’une des très nombreuses situations pour lesquelles de grandes quantités de données, traitées par apprentissage automatique, peuvent avoir des répercussions très concrètes et considérables sur les vies et les biens en cas de catastrophe.
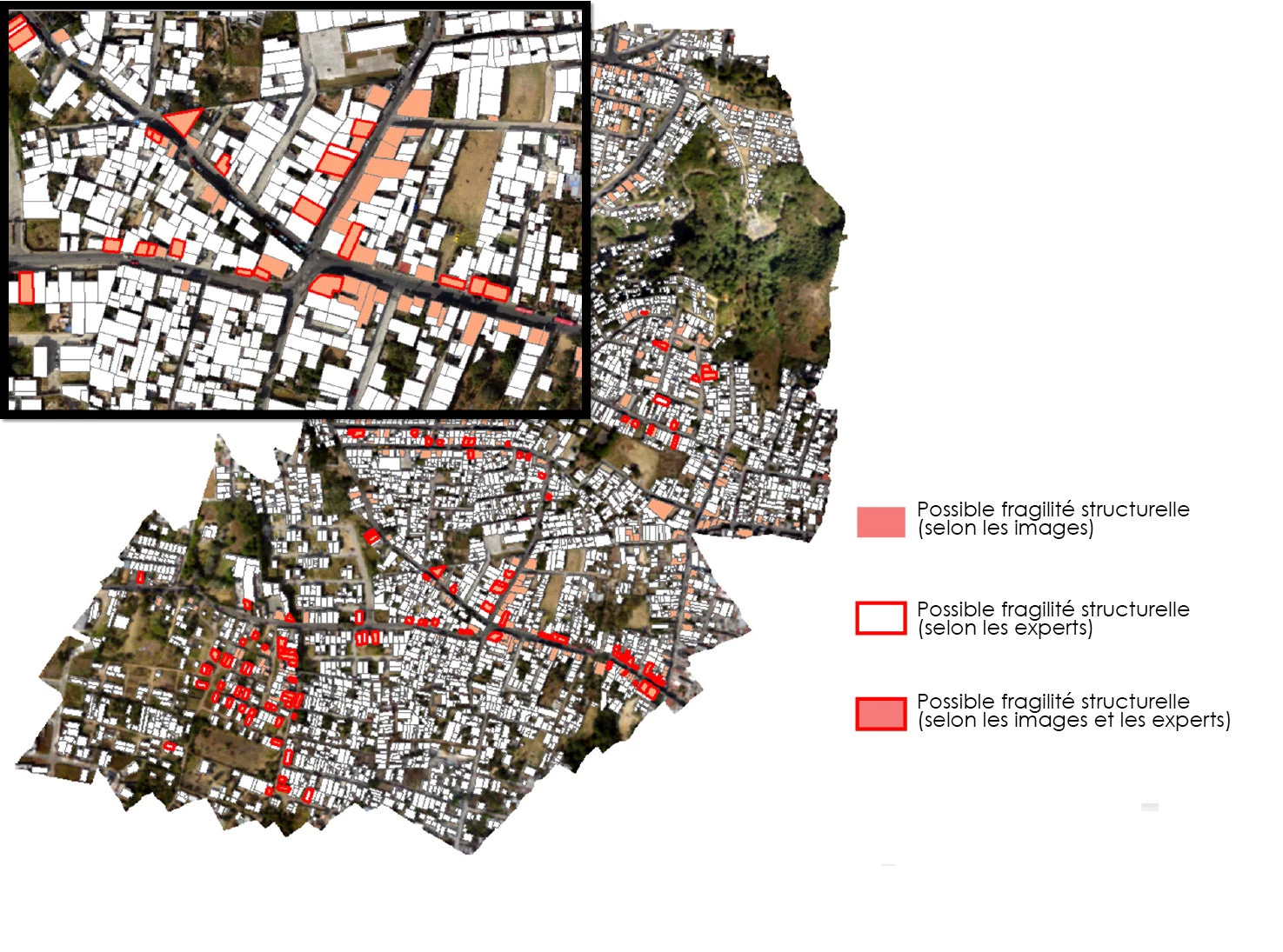
Dans une autre étude de cas, l’apprentissage automatique a été utilisé pour distinguer, à partir d’images satellite, les bidonvilles et autres implantations informelles des immeubles correspondant à une construction planifiée. Le projet était mis en œuvre par Jordan Graesser et le Oak Ridge National Laboratory (a), en coopération avec la Banque mondiale, et les méthodes utilisées sont à présent appliquées par l'équipe GOST pour analyser d'autres situations.

L’importance de ce type de travail ne doit pas être sous-estimée, car le fait de repérer sur une carte les quartiers les plus fragiles nous permet de définir plus précisément l’exposition des populations aux risques naturels. Une cartographie plus fine de la vulnérabilité est l’un des fondements d’une gestion plus efficace des risques de catastrophe. D'autres méthodologies de collecte d’informations précises sur la vulnérabilité ont connu un certain succès, par exemple en renforçant les effectifs sur le terrain pour faire des relevés ou en multipliant les campagnes de production collaborative (ou crowdsourcing) pour collecter des informations directement auprès des populations. Néanmoins, l’usage d’algorithmes d’apprentissage automatique permet de réduire considérablement les coûts, qu’ils soient appliqués à des images prises par des satellites ou des drones, à des photos à l’échelle de la rue ou bien à des données provenant de sources radicalement différentes, des capteurs sismiques aux réseaux sociaux.
Démocratiser les données et limiter les biais
L’Initiative pour le libre accès aux données et la résilience (OpenDRI) (a) de la GFDRR préconise l’utilisation intégrée de ces technologies pour maximiser l’impact des projets et minimiser les coûts. On peut et on doit associer de manière homogène les travaux de cartographie basée sur des algorithmes, les campagnes de cartographie communautaire pour collecter les données d’apprentissage et de validation, et l’analyse de ces données par des spécialistes. Les données d’apprentissage et de test sont utilisées pour « entraîner » les algorithmes d’apprentissage automatique, puis pour évaluer leur bon fonctionnement. Des connaissances spécialisées sont nécessaires pour recueillir des données sur le terrain, pour mettre en œuvre les logiciels d’apprentissage automatique et pour analyser les résultats de manière pertinente.
Le principe d’open data signifie que les données d’entrée et de sortie des projets doivent être en libre accès et faciles à utiliser. L’ouverture à toutes les parties prenantes du processus de gestion des risques de catastrophe permet de le démocratiser. La propriété des données revient ensuite aux communautés auxquelles elles se rapportent, ce qui favorise l’appropriation par la population des programmes de gestion des risques de catastrophe et, par conséquent, des recommandations qui en découlent. Le renforcement des capacités et le crowdsourcing sont des éléments essentiels des projets axés sur l’intégration de données ouvertes, car par définition ces activités associent les communautés à la création et au partage des données.
Par ailleurs, il est fondamental de réduire au minimum les risques de biais dans les projets. Ce n’est pas parce que des ordinateurs analysent et traitent les données grâce à l’apprentissage automatique que l’ensemble du processus est aseptisé et exempt de tout biais. Chacun sait que la qualité des modèles informatiques dépend de la qualité des données d’entrée, donc si ces dernières comportent des biais, ils seront aussi présents dans les résultats. Or ces biais peuvent influer sur les stratégies d’atténuation qui protègent les personnes et les communautés et, par conséquent, avoir de graves répercussions par la suite sur les pertes en vies humaines et en biens.
Bien plus que des expressions à la mode
L’intelligence artificielle et l’apprentissage automatique sont désormais dans toutes les bouches, un peu comme le « big data » et la « science des données » auparavant. En réalité, tous ces termes renvoient au même ensemble de méthodes informatiques fondées sur des statistiques et qui consistent à passer au crible, désagréger et exploiter des données. Les méthodes d’apprentissage automatique reposent simplement sur des programmes récursifs ou des algorithmes qui apprennent à partir de données d’entrée pour améliorer les résultats ultérieurs.
Commerce électronique, moteurs de recherche, publicités ciblées ou réseaux sociaux : les algorithmes d’apprentissage automatique alimentent déjà de vastes pans du web. Ils sont présents dans nos foyers, comme en témoigne le récent essor des dispositifs de domotique et des assistants vocaux. Ils le sont aussi dans nos téléphones mobiles, depuis les applications de commande vocale à celles de traduction instantanée, pour n’en citer que quelques-unes. Alors, pourquoi ne pas exploiter toute cette puissance de calcul pour mieux protéger les populations ?
POUR EN SAVOIR PLUS
- Ressources de l’OpenDRI (a)
- Publication : Machine Learning for Disaster Risk Management
- Billet : Three innovative approaches for managing disaster risks
- Vidéo : Ahmad Wani at UR2018: How artificial intelligence can help promote social inclusion


Prenez part au débat